MySQL 笔记
一、概述
(一)数据管理技术发展过程
1.数据管理
(1)定义:对数据进行收集、分类、组织、编码、存储、检索和维护一系列活动的总和;
(2)发展过程:人工管理阶段 -> 文件系统阶段 -> 数据库系统阶段
2.人工管理阶段
- 数据的管理者: 应用程序,数据不保存
- 数据面向的对象: 某一应用程序
- 数据的共享程度: 无共享、冗余度极大
- 数据的独立性: 不独立,完全依赖于程序
- 数据的结构化: 无结构
- 数据控制能力: 应用程序自己控制
3.文件系统阶段
- 数据的管理者: 文件系统,数据可长期保存
- 数据面向的对象: 某一应用程序
- 数据的共享程度: 共享性差、冗余度大
- 数据的结构化: 记录内有结构,整体无结构
- 数据的独立性: 独立性差,数据逻辑结构改变必须修改应用程序
- 数据控制能力: 应用程序自己控制
4.数据库系统阶段
(DBMS,独立的软件,位于操作系统之上)
- 数据结构化
- 数据的共享性高,冗余度低且易扩充
- 数据独立性高(应用程序和数据库分离)
- 数据由 DBMS 统一管理和控制
(二)数据库
1.数据(Data)
- 数据(Data)是数据库中存储的基本对象
- 数据的定义:描述事物的符号记录
- 数据的种类:文本、图形、图像、音频、视频、学生的档案记录、货物的运输情况等
- 数据的特点:数据与其语义是不可分的
2.数据库(Database)
- 数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据的集合
3.数据库管理系统(DBMS)
- 定义:位于用户和操作系统之间的一层数据管理软件,是数据库和用户之间的一个接口
- 属性:数据库管理系统和操作系统一样都属于计算机的基础软件,也是一个大型复杂的软件系统。
- 作用:在数据库建立、运用和维护时对数据库进行统一控制,以保证数据的完整性、安全性,并在多用户同时使用数据库时进行并发控制,在发生故障后对数据库进行恢复。
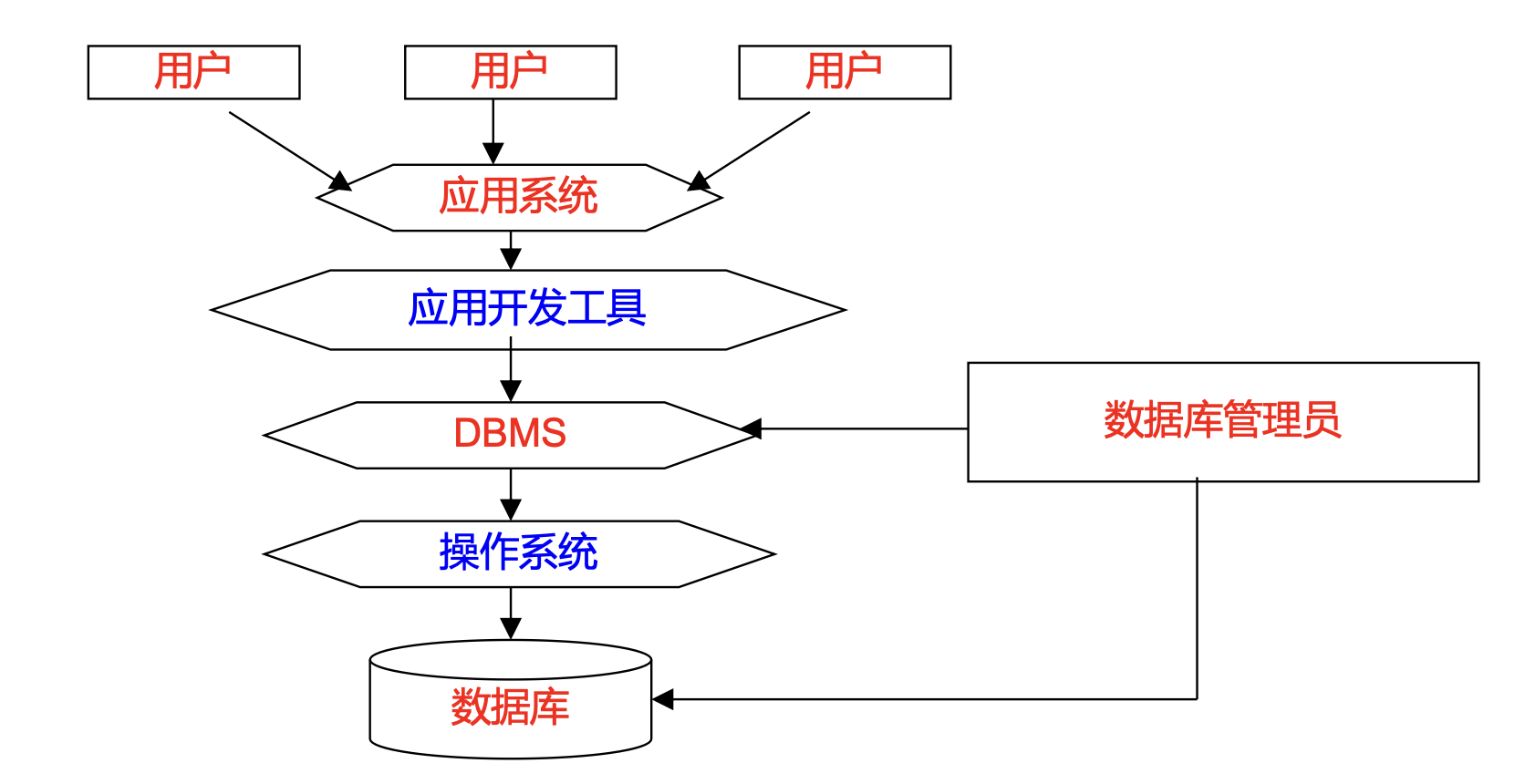
4.数据库系统(DBS)
数据库系统的构成
- 数据库
- 数据库管理系统(及其应用开发工具)
- 应用程序
- 数据库管理员
(三)MySQL 安装与配置
1.安装
(1)macOS
- macOS 安装 MySQL 教程
(2)Windows
- Windows 安装 MySQL 教程
2.连接
(1)终端
1 | mysql -u root -p |
(2)Navicat
(3)DataGrip
(4)VSCode
二、 MySQL 基础
(一)概念
DBMS 数据库管理系统
- 关系型数据库 SQL
- 非关系型数据库 noSQL
SQL: Structured Query Language 结构化查询语言
- 设定为 主键 的属性可以唯一地表示每一条记录,即用 主键 可以区分不同的记录
- 可以通过 外键 将两张表格的记录关联起来,
- 两张表间关联:表 A 中的 外键 对应到表 B 的 主键
- 一张表内关联:表A 中的 外键 也可以对应到自己的 主键 ,e.g 主管 id
- 主键可以有多个,无论几个,其目的都是通过 一个/组 主键 ,区分不同的记录
- 可以同时将某一个属性设置为 主键 和 外键,表示从 A 可以查到 B 的某一条记录,从 B 也可以反过来找到 A 中的对应记录
(二)MySQL 数据类型
数值
(1)整数
数据类型 字节数 TINYINT 1 SMALLINT 2 MEDIUMINT 3 INT 4 BIGINT 8 (2)浮点数
数据类型 字节数 FLOAT 4 DOUBLE 8 注:float / double(m, n) 带有小数点的数
m 表示该数字总共有几位数 n 表示小数部分所占的位数
e.g. float(3, 2) -> 2.33 就是总共有 3 位数,其中小数占了 2 位
(3)定点数 DECIMAL
注:DECIMAL(m, n) 带有小数点的数
m 表示该数字总共有几位数 n 表示小数部分所占的位数
e.g. DECIMAL(3, 2) -> 2.33
注:浮点数和定点数的区别
- float / double 在 db 中存储的是近似值,而 decimal 则是以字符串形式进行保存的。因此,浮点数可能会存在精度丢失的问题,而定点数则不会丢失精度。
- decimal(m,n) 的规则和 float / double 相同,但区别在 float / double 在不指定 m/n 时默认按照实际精度来处理,而 decimal 在不指定时默认为 decimal(10, 0)。
日期时间
数据类型 字节数 格式 备注 date 3 yyyy-MM-dd 存储日期值 time 3 HH:mm:ss 存储时分秒 year 1 yyyy 存储年 datetime 8 yyyy-MM-dd HH:mm:ss 存储日期+时间 timestamp 4 yyyy-MM-dd HH:mm:ss 存储日期+时间,时间戳 注 1 :datetime 和 timestamp 的区别:
- datetime 占8个字节,timestamp 占4个字节;
- 由于字节数区别,datetime 与 timestamp 能存储的时间范围也不同,datetime 的存储范围为 1000-01-01 00:00:00 — 9999-12-31 23:59:59,timestamp 存储的时间范围为 19700101080001—20380119111407;
- datetime 默认值为空,当插入的值为 null 时,该列的值就是 null;timestamp 默认值不为空,当插入的值为 null 的时候,mysql 会取当前时间;
- datetime 存储的时间与时区无关,timestamp 存储的时间及显示的时间都依赖于当前时区;
注 2 :通常表格中记录“创建时间”和“修改时间”字段时,用 timestamp
字符串
(1)CHAR(n) 定长字符串
(2)VARCHAR(n) 变长字符串
(3)TEXT
(4)BLOB 二进制对象(图片、视频、档案等)
注:
MySql 单行最大数据量为 64K,为了存储大数据,因此创建了 TEXT 和 BLOB 两种类型;
TEXT 和 VARCHAR 比较类似,当 varchar(M) 的 M 大于某些数值时,varchar 会自动转为 text:
M>255 时转为 tinytext
M>500 时转为 text
M>20000 时转为 mediumtext
varchar(M) 和 text 的区别:
单行 64K 即 65535 字节的空间,varchar 只能用 63352 / 65533 个字节,text 可以用 65535 个字节;
text 可以指定 text(M) ,且 M 无限制
text 不允许有默认值,varchar 允许有默认值
text 和 blob 的区别:text 存储的是字符串而 blob 存储的是二进制字符串。
JSON
空间
(三)SQL 语句分类
DDL (Data Definition Language) 数据定义语言
CREATE / DROP / ALTER / TRUNCATE
DML (Data Manipulation Language) 数据操作语言
INSERT / UPDATE / DELETE / CALL
DQL (Data Query Language) 数据查询语言
SELECT
DCL (Data Control Language) 数据控制语言
GRANT / REVOKE
三、常用 SQL 语句
(一)数据库和表操作
新建数据库
1
CREATE DATABASE `sql_tutorial`;
查看所有数据库
1
SHOW DATABASES;
删除数据库
1
DROP DATABASE `sql_tutorial`;
1
2mysql> drop database test;
ERROR 1010 (HY000): Error dropping database (can't rmdir './test/', errno: 17)注:如果遇到上述无法删除数据库的情况,是因为 test 目录下存在着MySQL 不知道的文件,即 MySQL 中没有该文件的数据字典信息,需要手动删除。
1
2
3cd /usr/local/mysql/data/test # 进入 test 所在位置
ls # 查看未知文件
rm -rf xxx # 手动删除删除后,再次 DROP 即可。
选择数据库
1
USE `sql_tutorial`;
创建表格
1
2
3
4
5
6CREATE TABLE `student` (
`student_id` INT PRIMARY KEY, # `属性名` 类型 主键,
`name` VARCHAR ( 20 ),
`major` VARCHAR ( 20 )
# PRIMARY KEY(`student_id`) 主键也可以不在属性后注明,也可以在下面单独写
);查看表格
1
2DESCRIBE `student`;
DESC `student`;删除表格
1
DROP TABLE `student`;
新增表 字段
1
ALTER TABLE `student` ADD COLUMN gpa DECIMAL(3,2);
删除表 字段
1
ALTER TABLE `student` DROP COLUMN gpa;
修改表 字段属性
1
ALTER TABLE `student` MODIFY COLUMN gpa FLOAT(3,1);
修改表 字段名
1
ALTER TABLE `student` RENAME COLUMN gpa to Stu_GPA;
导出数据库
1
2在 Shell 中使用
mysqldump -u root -p DB (able) > DB.sql导入数据库
1
2在 Shell 中使用
mysql -u root -p DB < DB.sql
(二)数据操作
查询所有记录
1
SELECT * FROM `student`;
添加记录
不指定属性
1
2# 这种方式添加记录,属性的顺序和数量必须全部匹配
INSERT INTO `student` VALUES(1, '小白', '历史');指定属性
1
2
3
4
5# 可以在表格后添加属性序列,指定输入的属性,如后续值省略,则自动填入默认值
INSERT INTO `student`(`name`, `major`, `student_id`) VALUES('小蓝', '英语', 4);
# 插入多条数据
INSERT INTO `student`(`name`, `student_id`) VALUES('小红', 5),('小绿', 6),('小黄', 7);
常用约束
1
2
3
4
5
6
7CREATE TABLE `student`
(
`student_id` INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL, # 非空
`major` VARCHAR(20) UNIQUE, # 唯一
`sex` VARCHAR(10) DEFAULT '男' # 默认值,通常应用在指定输入属性时
);更新记录
1
2
3UPDATE `student`
SET `major` = 'English', `score` = 98
WHERE `major` = 'Math' OR `major` = 'Chinese';删除记录
1
2DELETE FROM `student`
WHERE `student_id` = 4; # 不加条件,则删除所有记录查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT 属性1, 属性2
FROM 表
WHERE 属性1 = '特定值' AND / OR 属性2 <> '特定值'
# 链接符优先级 NOT > AND > OR,可以用括号改变优先级顺序
# 增加筛选条件( <> 不等于 )
# 同一属性 a 判断多个条件并使用 OR 连接时,可以用: 属性 IN ('', '', '')
# 属性在某个区间内取值时,可以用: BETWEEN a AND b
GROUP BY 分组依据
HAVING 分组后过滤的依据
ORDER BY 排序依据1, 排序依据2 DESC
# 默认升序 ASC ,添加 DESC 变为降序
# 先按照依据1排序,有相同的再按照依据2排序
LIMIT n / a,b
# 如果只写一个数字 n 则返回前 n 条记录
# 如果写 a,b 则返回 从 a+1 条记录开始的 b 条记录
注:
- 判断是否为空用
IS NULL / IS NOT NULL;- 计算字符串中字符数的最佳函数是
CHAR_LENGTH(str),它返回字符串str的长度;而函数LENGTH(str)返回字符串str的字节数,某些字符包含多于 1 个字节,可能导致返回结果错误。- DISTINCT + 属性 可用于去重;
(三)进阶操作
聚合函数
聚合函数用于对某些列进行一些计算,包括求和、计数、求平均等。
COUNT( ) 返回集合中的项目数;
AVG( ) 返回集合的平均数;
SUM( ) 求和;
ROUND( 对象, 小数位数 ) 四舍五入保留小数;
MIN( ) 最小值;
MAX( ) 最大值;
通配符
1
2
3属性 (NOT) LIKE '通配符';
# % 表示任意长度的字符串
# _ 表示任意单个字符正则表达式
1
2
3
4
5
6属性 REGEXP '正则表达式';
# ^ 开头 $ 结尾
# . 任意一个字符
# [abc] 其中任意一个字符
# [a-z] 范围内任意一个字符
# A|B A 或 B集合运算
UNION 并集
将两个结果合并为一个结果返回,后者直接接在前者最后;
1
2
3SELECT 属性1 FROM 表1
UNION
SELECT 属性2 FROM 表2;注:
UNION 默认会去除两条 select 中得到的重复记录;如果要求不去重,则可以使用 UNION ALL。
INTERSECT 交集
将两个结果取交集后返回;
1
2
3SELECT 属性1 FROM 表1
INTERSECT
SELECT 属性2 FROM 表2;EXCEPT 差集
将两个结果取差集后返回,查找满足第一条语句但不满足第二条语句的记录;
1
2
3SELECT 属性1 FROM 表1
EXCEPT
SELECT 属性2 FROM 表2;
连接查询 JOIN
连接查询,将后者拼接在前者表的右边
(1)外连接
- LEFT JOIN(左连接)以左表为主,右表中没有的数据用 NULL 填充;
- RIGHT JOIN(右连接)以右表为主,左表中没有的数据用 NULL填充;
- FULL (OUTER) JOIN(全连接)两边连接,没有的都用 FULL 填充 并集。
(2)内连接
- INNER JOIN (内连接)只返回两个表中都有的数据 交集
1
2
3
4
5
6
7
8
9
10
11
12
13SELECT 属性1, 属性2, 属性3 FROM 表1
INNER JOIN 表2
ON 表1.属性a = 表2.属性b;
# INNER JOIN 内连接 也可以用 WHERE 的方式实现
# INNER JOIN
SELECT * FROM player
INNER join equip
on player.id = equip.player_id;
# WHERE
select * from player, equip
where player.id = equip.player_id;(3)交叉连接
(CROSS) JOIN (交叉连接)相当于取两个表的***笛卡尔积***
注:在 MySQL 中,如果不指定 ON 条件,则 CROSS JOIN 与 INNER JOIN 的结果是一样的,都是两张表的笛卡尔积。
1
2
3SELECT 属性1, 属性2, 属性3 FROM 表1
(CROSS) JOIN 表2
ON 表1.属性a = 表2.属性b;子查询 / 嵌套查询
(1)一个查询嵌套在另一个查询中
1
2
3
4
5
6
7
8
9
10
11
12# 查询对一位客户销售金额超过 50000 的员工姓名
SELECT Employee.name, Works_with.total_sales
FROM Employee LEFT JOIN Works_with
ON Employee.emp_id = Works_with.emp_id
WHERE Employee.emp_id IN
(
SELECT Works_with.emp_id
FROM Works_with
WHERE Works_with.total_sales >= 50000
);
# 注: 这里内层的查询结果不止一个,所以不能用 = 连接内外查询,要用 IN 连接内外查询(2)用子查询结果创建新表格
1
2
3
4
5# 查询所有等级小于 5 级的玩家,并将结果保存到新的表格中
CREATE TABLE new_player SELECT * FROM player WHERE level < 5;
# 查询所有等级在 6-10 级的玩家,并将结果插入到 new_player 中
INSERT INTO new_player SELECT * FROM player WHERE level BETWEEN 6 AND 10;索引 INDEX
通常对一张表格的主键字段或常用字段创建索引,从而提高后续的查询效率。
1
2
3
4
5
6
7
8
9
10# 在指定表(的某些字段)上创建 唯一/全文/空间 索引
CREATE [UNIQUE|FULLTEXT|SPATIAL] INDEX 索引名称
ON 表名 (字段名称, ...);
# 查看索引
SHOW INDEX FROM 表名;
# 删除索引
DROP INDEX 索引名称
ON 表;
(四)窗口函数
概念
窗口函数是一种特殊类型的 SQL 函数,它在查询结果集中的一定窗口(或称为窗口框架)上执行计算操作。
这个窗口是通过使用 OVER 子句定义的,它指定了在进行聚合、排序或分析等操作时应考虑的行集合。
窗口函数通常与聚合函数一起使用,但与普通的聚合函数不同,它不会将整个结果集作为输入,而是基于定义的窗口框架对子集进行计算。这使得在不引入子查询或自连接的情况下,能够在每一行上执行对整个结果集的聚合或分析操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14SELECT
column1,
column2,
SUM(column3) OVER (PARTITION BY column1 # 按 column1 分组
ORDER BY column2 # 按 column2 排序
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING # 当前行及其前后各一行
) AS running_total
FROM
your_table;
# SUM 是一个聚合函数,但它通过OVER子句指定了一个窗口框架。
# 在这个例子中,窗口由 PARTITION BY column1 定义,然后使用 ORDER BY column2 排序。
# ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING指定了窗口的范围,表示当前行及其前后各一行。
# 这样,SUM函数将在每个窗口内计算列column3的累计和。聚合函数
示例数据

SUM1
2
3
4
5
6SELECT *,
SUM(Salary) OVER(PARTITION BY GroupName) AS 部门工资总和, # 按照部门分组,计算部门工资总和
SUM(Salary) OVER(PARTITION BY GroupName ORDER BY ID) AS 累加_部门工资总和, # 按照部门分组,再按组内 ID 依次累加部门工资总和
SUM(Salary) OVER(ORDER BY ID) AS 累加_全体工资总和, # 按所有人的 ID 依次累加工资总和
SUM(Salary) OVER() AS 全体工资总和 # 窗口为空,直接计算所有员工工资总和 等同于 SUM()
FROM Emp;
MAXMINCOUNT1
2
3
4
5
6SELECT *,
COUNT(*) OVER(PARTITION BY GroupName) AS 部门人数,
COUNT(*) OVER(PARTITION BY GroupName ORDER BY ID) AS 累加_部门人数,
COUNT(*) OVER(ORDER BY ID) AS 累加_全体人数,
COUNT(*) OVER() AS 总人数
FROM Emp;
AVG
排序函数
示例数据

ROW_NUMBER将 SELECT 得到的数据进行排序,必须与 ORDER BY 连用,常用于分页查询;1
2
3
4SELECT *,
ROW_NUMBER() over (PARTITION BY ClassName ORDER BY Score DESC) AS 班内排名, # 按照班级分组,再按照分数降序排列,给每行一个排名
ROW_NUMBER() over (ORDER BY Score DESC) AS 全体排名 # 按照分数降序排列,给每行一个排名
FROM SCO;
RANK与 ROW_NUMBER 类似,但是允许并列排名,即分数相同时,排名也相同,后续跳过被占用的名次;1
2
3# ROW_NUMBER
SELECT *, ROW_NUMBER() OVER (ORDER BY SCO.Score DESC) AS 总排名
FROM SCO; # 不能并列排名
1
2
3# RANK
SELECT *, RANK() over (ORDER BY SCO.Score DESC) AS 总排名
FROM SCO; # 可以并列,且后续跳过被占用的排名
DENSE_RANK与 RANK 类似,允许并列排名,但后续不会跳过被占用的名次。1
2
3# DENSE_RANK
SELECT *, DENSE_RANK() over (order by SCO.Score DESC ) AS 总排名
FROM SCO; # 可以并列,且后续不跳过被占用的排名
取值函数
(1)向前向后取数
lag( )返回窗口内当前行之前的第 N 行数据lead( )返回窗口内当前行之后的第 N 行数据
(2)First_value & Last_value
First_value返回窗口内第一行数据,可以用 Min 聚合函数替代Last_value返回窗口内最后一行数据,可以用 Max 聚合函数替代
(五)函数
substr( 属性 a, begin, n )截取属性 a 从 begin 位置开始的 n 个字符,e.g. 查找姓氏 substr(name, 1, 1);datediff( 日期 1, 日期 2 )前减后,得到的结果是日期 1 与日期 2 相差的天数。如果日期 1 比日期 2 大,结果为正;如果日期 1 比日期 2 小,结果为负。timestampdiff(时间类型, 日期1, 日期2)后减前在“时间类型”的参数位置,通过添加“day”, “hour”, “second”等关键词,来规定计算天数差、小时数差、还是分钟数差。日期 1 大于日期 2 ,结果为负,日期 1 小于日期 2 ,结果为正。IFNULL( 判断对象 A, 替换值 N )如果判断对象 A 的值为 NULL,则返回替换值 N。mod( 操作对象 A, 取模数 n ) = x判断操作对象 A 对 n 取模的结果是否为 x,等价于 A % n = x。
(六)视图
- 创建视图的目的是将查询结果保存为一张虚拟的表,当后续需要使用该查询结果时,就可以直接从视图中调用,做进一步的查询。
- 视图是动态变化的,随着原表的修改而修改。
1 | # 创建视图 |
 微信
微信- 支付宝

