Python 学习笔记
1. 基础
1.1 编码 / 标识符 / 保留字
- 默认情况下,Python 3 源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串;
- 标识符
- 第一个字符必须是字母表中字母或下划线_
- 标识符的其他的部分由字母、数字和下划线组成
- 标识符对大小写敏感
- 保留字即关键字,不能把它们用作任何标识符名称。
1
2import keyword
print(keyword.kwlist)
1.2 注释
- 单行注释以 # 开头
- 多行注释可以用多个#号,或者三个单 / 双引号 ‘’’ 和 “”"
- 多行注释中不能再嵌套多行注释,但可以使用单行注释 #
- 输出函数的注释
1
2
3
4
5def a():
'''函数注释'''
pass
print(a.__doc__)
1.3 多行语句
- Python 通常是一行写完一条语句,但如果语句很长,可以使用反斜杠来实现多行语句
1
2
3total = item_one + \
item_two + \
item_three - 在 [], {}, 或 () 中的多行语句,不需要使用反斜杠 \
1
2total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
1.4 输出
1.4.1 基本输出
- Python 使用 print 输出内容,默认输出是换行的;
- 要实现不换行,则需要在变量末尾加上
end="";1
2
3
4# 换行输出
print( x )
# 不换行输出
print( x, end="" )
1.4.2 输出格式调整
转为字符串
- str():函数返回一个用户易读的表达形式;
- repr():产生一个解释器易读的表达形式;
zfill( )
- 该函数会在数字的左边填充 0;
str.format()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 1. 参数替换
print('{}网址: "{}!"'.format('AngFff', 'www.angfff.top'))
# 输出: AngFff网址: "www.angfff.top!"
# 2. 数字标明位置
print('{0} 和 {1}'.format('Google', 'Apple'))
# 输出:Google 和 Apple
# 3. 关键字指定参数
print('{name}网址:{site}'.format(name='AngFff', site='123'))
# AngFff网址:123
# 4. 可选项,进一步控制格式
# 将 Pi 保留到小数点后三位
import math
print('常量 PI 的值近似为 {0:.3f}。'.format(math.pi))
# 输出:常量 PI 的值近似为 3.142。
# 5. 控制宽度
table = {'Google': 1, 'Runoob': 2, 'Taobao': 3}
for name, number in table.items():
print('{0:10} ==> {1:10d}'.format(name, number))
# 输出:
# Google ==> 1
# Runoob ==> 2
# Taobao ==> 3- 括号及其里面的字符 (称作格式化字段) 将会被 format() 中的参数替换;
- 在括号中的数字用于指向传入对象在 format() 中的位置;
- 如果在 format() 中使用了关键字参数, 那么它们的值会指向使用该名字的参数,位置及关键字参数可以任意的结合;
- !a (使用 ascii()), !s (使用 str()) 和 !r (使用 repr()) 可以用于在格式化某个值之前对其进行转化;
- 可选项 : 和格式标识符可以跟着字段名,允许对值进行更好的格式化;
- 在 : 后传入一个整数, 可以保证该域至少有这么多的宽度;
1.5 输入
1.5.1 标准输入
input( ) 内置函数 从标准输入读入一行文本
1
2str = input("请输入:")
print("输入内容为:", str)
1.5.2 文件读写
创建文件对象
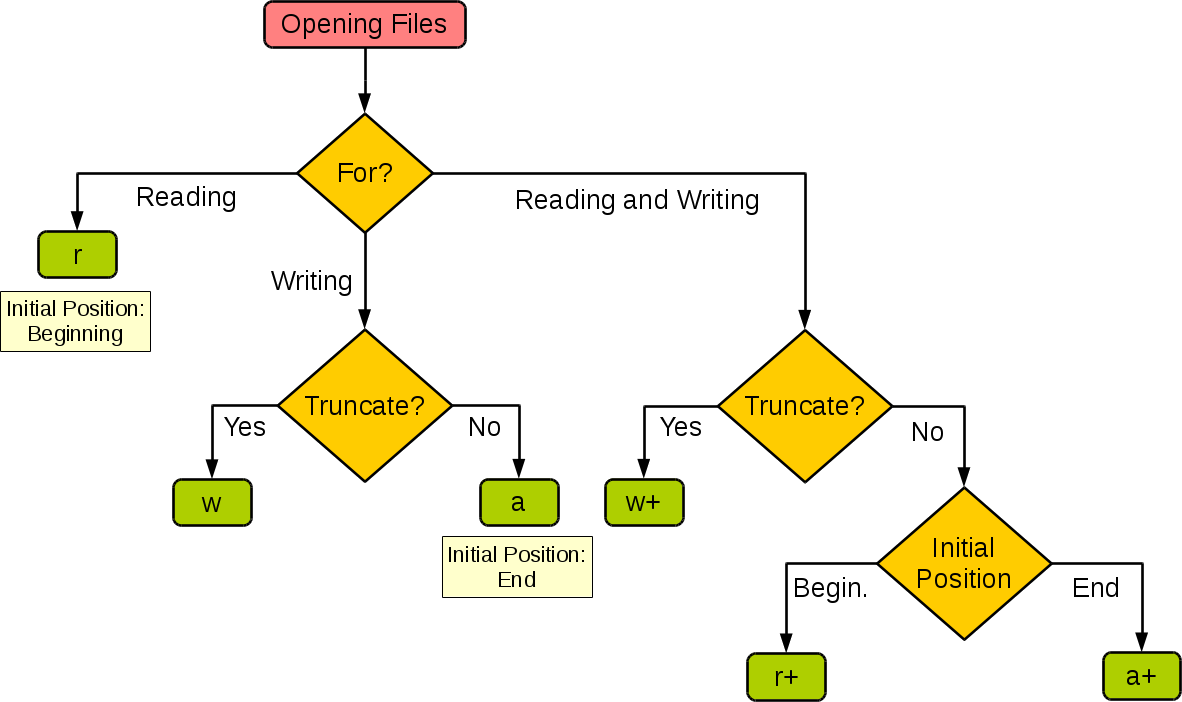
- open() 将会返回一个 file 对象
open(filename, mode) - filename:要打开的文件名
- mode:决定了打开文件的模式,只读 ‘r’,写入 ‘w’,追加 ‘a’ 等。该参数是非强制的,默认文件访问模式为只读 ‘r’
- 每次打开文件后,都需要关闭文件对象,调用
f.close()

- open() 将会返回一个 file 对象
针对文件对象进行读取
- 在已创建 文件对象 的情况下 f = open()
- f.read()
- 调用 f.read(size),将读取一定数目的数据,然后作为字符串或字节对象返回
- size 是一个可选的数字类型的参数,当 size 为空或者负,则该文件的所有内容都将被读取并且返回
- f.readline()
- f.readline() 会从文件中读取单独的一行,换行符为 ‘\n’
- 如果返回一个空字符串,说明已经已经读取到最后一行
- f.readlines()
- f.readlines() 将返回该文件中包含的所有行
- 如果设置可选参数 sizehint,则读取指定长度的字节,并且将这些字节按行分割
针对文件对象进行写入
- 在已创建 文件对象 的情况下 f = open()
- f.write()
- f.write(string) 将 string 写入到文件中,然后返回写入的字符数
- f.tell()
- f.tell() 用于返回文件当前的读/写位置(即文件指针的位置)
- 文件指针表示从文件开头开始的字节数偏移量
- f.seek()
- 要改变文件指针的位置,可以用 f.seek(offset, whence)
- offset 表示相对于 whence 参数的偏移量,whence 如果是 0 表示开头,如果是 1 表示当前位置, 2 表示文件的结尾
- seek(x,0):从起始位置即文件首行首字符开始移动 x 个字
- seek(x,1):表示从当前位置往后移动 x 个字符
- seek(-x,2):表示从文件的结尾往前移动 x 个字符
关闭文件
- 在已创建 文件对象 的情况下 f = open()
- f.close()
- 调用 f.close() 来关闭文件并释放系统的资源
- with 关键字用于简化文件操作并确保文件在使用完后自动关闭,避免手动调用 close() 方法。它会在代码块执行结束后自动管理资源的释放,即使代码中发生异常,也能保证文件被正确关闭
1
2
3with open('/test.txt','r') as f:
read_data = f.read()
# 运行结束后,会自动关闭 f 对象,释放资源
1.6 运算符
算数运算符
运算符 描述 + 加 - 两个对象相加 - 减 - 得到负数或是一个数减去另一个数 * 乘 - 两个数相乘或是返回一个被重复若干次的字符串 / 除 - x 除以 y % 取模 - 返回除法的余数 ** 幂 - 返回x的y次幂 // 取整除 - 向下 / 左取整 比较(关系)运算符
运算符 描述 == 等于 - 比较对象是否相等 != 不等于 - 比较两个对象是否不相等 > 大于 - 返回x是否大于y < 小于 - 返回x是否小于y >= 大于等于 - 返回x是否大于等于y <= 小于等于 - 返回x是否小于等于y 赋值运算符
运算符 描述 = 简单的赋值运算符 += 加法赋值运算符 -= 减法赋值运算符 *= 乘法赋值运算符 /= 除法赋值运算符 %= 取模赋值运算符 **= 幂赋值运算符 //= 取整除赋值运算符 := 海象运算符,这个运算符的主要目的是在表达式中同时进行赋值和返回赋值的值。Python3.8 版本新增运算符 位运算符
运算符 描述 实例(a=12 / b=13) & 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 (a & b) 输出结果 12 ,二进制解释: 0000 1100 | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1。 (a | b) 输出结果 61 ,二进制解释: 0011 1101 ^ 按位异或运算符:当两对应的二进位相异时,结果为1 (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 ~ 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1。~x 类似于 -x-1 (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 << 左移动运算符:运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 a << 2 输出结果 240 ,二进制解释: 1111 0000 >> 右移动运算符:把">>“左边的运算数的各二进位全部右移若干位,”>>"右边的数指定移动的位数 a >> 2 输出结果 15 ,二进制解释: 0000 1111 逻辑运算符
运算符 逻辑表达式 描述 and x and y 布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 or x or y 布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 not not x 布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 成员运算符
运算符 描述 in 如果在指定的序列中找到值返回 True,否则返回 False。 not in 如果在指定的序列中没有找到值返回 True,否则返回 False。 身份运算符
运算符 描述 is is 是判断两个标识符是不是引用自一个对象 is not is not 是判断两个标识符是不是引用自不同对象
2. 基本数据类型
2.1 数字(Number)
- int (整数)
- 只有一种整数类型 int,表示为长整型,没有 Long
- bool (布尔)
- bool 是 int 的子类,True / 1 和 False / 0 可以和数字相加
- float (浮点数)
- 如 1.23、3E-2
- complex (复数)
- 如 1 + 2j、 1.1 + 2.2j
函数 返回值 ( 描述 ) abs(x) 返回数字的绝对值,如abs(-10) 返回 10 ceil(x) 返回数字的上入整数,如math.ceil(4.1) 返回 5 cmp(x, y) 如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 Python 3 已废弃,使用 (x>y)-(x<y) 替换。 exp(x) 返回e的x次幂(ex),如math.exp(1) 返回2.718281828459045 fabs(x) 以浮点数形式返回数字的绝对值,如math.fabs(-10) 返回10.0 floor(x) 返回数字的下舍整数,如math.floor(4.9)返回 4 log(x) 如math.log(math.e)返回1.0,math.log(100,10)返回2.0 log10(x) 返回以10为基数的x的对数,如math.log10(100)返回 2.0 max(x1, x2,…) 返回给定参数的最大值,参数可以为序列。 min(x1, x2,…) 返回给定参数的最小值,参数可以为序列。 modf(x) 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示。 pow(x, y) x**y 运算后的值。 round(x [,n]) 返回浮点数 x 的四舍五入值,如给出 n 值,则代表舍入到小数点后的位数。
其实准确的说是保留值将保留到离上一位更近的一端。sqrt(x) 返回数字x的平方根。
2.2 字符串(String)
- 字符串用单引号 ’ 或双引号 " 括起来,单引号 ’ 和双引号 " 的使用完全相同,使用三引号(‘’’ 或 “”")可以指定一个多行字符串;
- 使用反斜杠 \ 转义特殊字符,使用 r 可以让反斜杠不发生转义。 如 r"this is a line with \n" 则 \n 会显示,并不是换行;
- 字符串的截取 / 切片
字符串[start:end:step],左含右不含、步长参数 step,step 为负数时表示逆向;- 索引值以 0 为开始值,-1 为从末尾的开始位置;
- 加号 + 是字符串的连接符, 星号 * 表示复制当前字符串;
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串;
- 字符串不能通过索引赋值、修改元素值;
2.3 布尔(Bool)
- 布尔类型只有两个值:True 和 False,等价于 1 和 0;
- 布尔类型可以转换成其他数据类型;
- 使用
bool()函数将其他类型的值转换为布尔值; - 布尔类型可以和逻辑运算符一起使用,包括 and、or 和 not;
2.4 列表(List)
- 列表写在方括号 [] 之间、用逗号分隔元素;
- 列表中的元素类型可以互不相同;
- 列表可以通过索引赋值、修改元素值;
- 列表的截取 / 切片
列表[start:end:step],左含右不含、步长参数 step,step 为负数时表示逆向;- 索引值以 0 为开始值,-1 为从末尾的开始位置;
- 加号 + 是列表的连接符, 星号 * 表示复制当前列表;
2.5 元组(Tuple)
- 元组写在小括号 () 之间、用逗号分隔元素;
- 元组中的元素类型可以互不相同;
- 元组不能通过索引赋值、修改元素值;
- 元组的截取 / 切片
元组[start:end:step],左含右不含、步长参数 step,step 为负数时表示逆向;- 索引值以 0 为开始值,-1 为从末尾的开始位置;
- 加号 + 是元组的连接符, 星号 * 表示复制当前元组;
- 构造包含 0 个或 1 个元素的元组比较特殊
1
2tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
2.6 集合(Set)
- 集合写在大括号 {} 之间、用逗号分隔元素,另外也可以使用
set()函数创建集合; - 创建一个空集合必须用
set()而不是{ },{ }用于创建空字典; - 集合是一种无序、可变的数据类型,其中的元素不会重复;
- 集合运算
- 交集 &
- 并集 |
- 差集 -
- 两集合中不同时存在的元素 ^
2.7 字典(Dictionary)
- 字典是一种映射类型,字典用
{ }标识,它是一个无序的 键(key) : 值(value) 的集合; - 在同一个字典中,键必须是唯一的,且键必须使用不可变类型;
- 字典的创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15dict1 = {}
dict1['one'] = "1 A"
dict1[2] = "2 F"
dict2 = {'name': 'Ang', 'age': '18'}
# 字典推导式
dict3 = {x: x**2 for x in (2, 4, 6)}
x = ['A','B','C','D']
y = ['a','b','c','d']
dict4 = {i:j for i,j in zip(x,y)}
# dict 函数
dict5 = dict(Runoob=1, Google=2, Taobao=3) - 键值对输出
1
2
3
4dic1 = {'a': 1, 'b': 2, 'c': 3}
# 输出
for k,v. in dict1.items():
print(k, ':', v)
3. 基本数据类型的转换
3.1 隐式类型转换
- 对两种不同类型的数据进行运算时,较低数据类型会转换为较高数据类型以避免数据丢失;
- 当整数与浮点数进行运算时,整数会被自动转换为浮点数;
- 布尔值在与数字进行运算时会被自动转换为整数,
True被视为1,False被视为0;
- 数据类型的高低:bool < int < float < complex
3.2 显式类型转换
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个 (key, value)元组序列。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
4. 条件控制
4.1 if-elif-else
1 | if condition_1: |
- 每个条件后面要使用冒号,表示接下来是满足条件后要执行的语句块。
- 如果 if 的执行语句只有一句,可以写在 if 的同一行。
4.2 match-case
1 | match subject: |
- case _: 类似于 C 和 Java 中的 default:,当其他 case 都无法匹配时,匹配这条,保证永远会匹配成功。
5. 循环语句
5.1 while
1 | while <expr>: |
- 如果 while 的执行语句只有一句,可以写在 while 的同一行。
5.2 for
1 | for item in iterable: |
5.3 break & continue & pass
- break 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。
- continue 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
- pass 不做任何事情,一般用做占位语句。
6. 推导式
6.1 列表推导式
1 | [表达式 for 变量 in 列表] |
e.g. 过滤掉长度小于或等于3的字符串列表,并将剩下的转换成大写字母
1 | names = ['Bob','Tom','alice','Jerry','Wendy','Smith'] |
6.2 字典推导式
1 | { key_expr: value_expr for value in collection } |
e.g. 将列表中各字符串值为键,各字符串的长度为值,组成键值对
1 | listdemo = ['Google','Runoob', 'Taobao'] |
6.3 集合推导式
1 | { expression for item in Sequence } |
e.g. 判断不是 abc 的字母并输出
1 | a = {x for x in 'abracadabra' if x not in 'abc'} |
6.4 元组推导式
1 | (expression for item in Sequence ) |
- 元组推导式返回的结果是一个生成器对象,使用 tuple() 函数,可以直接将生成器对象转换成元组;
e.g. 生成一个包含数字 1~9 的元组
1 | t = (x for x in range(1, 10)) |
7. 迭代器 & 生成器
7.1 迭代器
(1)概念
在 Python 中,迭代器(Iterator)是一种用于遍历集合(如列表、元组、字典等)元素的对象。迭代器遵循迭代协议,主要包括两个方法:
__iter__()和__next__()。下面是对迭代器的详细解释:
- 迭代器的基本概念
- 迭代器对象:实现了
__iter__()和__next__()方法的对象。- 可迭代对象:实现了
__iter__()方法的对象,可以返回一个迭代器。
- 迭代器的工作原理
__iter__()方法:返回迭代器对象本身。通常在可迭代对象上调用时会返回一个迭代器。__next__()方法:返回序列中的下一个值。如果没有更多的值可返回,应该抛出StopIteration异常。
(2)从集合生成迭代器
- 可迭代对象:可以使用
for循环遍历的对象,如列表、元组、字典、集合等。可迭代对象实现了__iter__()方法。 - 基本方法:iter();next()
e.g. 从列表生成迭代器
1 | # 原列表 |
(3)创建自定义迭代器
- 通过定义一个类并实现 _iter_\ 和 _next_\ 两个方法来创建自定义迭代器。例如:
1 | # 创建迭代器 |
(4)迭代器与可迭代对象的区别
- 可迭代对象:可以使用
for循环遍历的对象,如列表、元组、字典、集合等。可迭代对象实现了__iter__()方法。 - 迭代器:是可迭代对象的一个实现,具有
__iter__()和__next__()方法。迭代器可以在遍历时保持状态。
7.2 生成器
(1)概念
在 Python 中,生成器(Generator)是一种特殊类型的迭代器,用于创建可迭代的序列。生成器的主要特点是它们使用
yield语句来返回值,而不是使用return语句。生成器在每次调用时会记住上一次的状态,从而实现惰性求值。
- 生成器函数:使用
yield语句定义的函数。调用生成器函数不会立即执行,而是返回一个生成器对象。- 生成器对象:可以被迭代的对象,支持
__iter__()和__next__()方法。
(2)创建生成器
- 生成器函数的定义与普通函数类似,但使用
yield语句来返回值
1 | import sys |
(3)生成器的工作原理
- 当调用生成器函数时,函数体不会立即执行,而是返回一个生成器对象。
- 每次调用生成器对象的
__next__()方法时,函数会从上次yield语句停止的地方继续执行,直到遇到下一个yield语句。 - 当没有更多的
yield语句可执行时,生成器会抛出StopIteration异常,表示迭代结束。
8. 函数
8.1 定义 / 调用函数
1 | # 定义函数 |
python 函数的参数传递:
不可变类型:类似 C++ 的值传递,不可变类型对象包括 整数、字符串、元组。对于不可变类型对象 a,调用 fun(a) 时,传递的只是 a 的值,没有影响 a 对象本身。如果在 fun(a) 内部修改 a 的值,则是新生成一个 a 的对象,函数外部的 a 不会受影响。
可变类型:类似 C++ 的引用传递,可变类型对象包括 列表,字典。对于可变类型对象 b,调用 fun(b) 时,则是将 b 真正的传过去,修改后 fun 外部的 b 也会受影响。
8.2 函数参数
(1)必需参数
- 必需参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样,否则会因缺少参数而报错。
(2)关键字参数
- 关键字参数和函数调用关系紧密,函数调用使用关键字参数来确定传入的参数值。
- 使用关键字参数允许函数调用时参数的顺序与声明时不一致,因为 Python 解释器能够用参数名匹配参数值。
e.g.
1 | # 可写函数说明 |
(3)默认参数
- 调用函数时,如果没有传递参数,则会使用默认参数
(4)不定长参数
1 | # 一个 * 的参数会以元组形式导入 |
- 加了星号 * 的参数会以元组(tuple)的形式导入,存放所有未命名的变量参数
- 可以不向函数传递未命名的变量,如果在函数调用时没有指定参数,它就是一个空元组
- 加了两个星号 ** 的参数会以字典的形式导入
- 如果单独出现星号 * ,则星号 * 后的参数必须用关键字传入
- 强制位置参数:Python3.8 新增了一个函数形参语法 / 用来指明函数形参必须使用指定位置参数,不能使用关键字参数的形式。
8.3 lambda 匿名函数
(1)概念
在 Python 中,lambda 函数是一种小型、匿名的、内联函数,它可以具有任意数量的参数,但只能有一个表达式。与常规的函数定义(使用 def 关键字)相比,lambda 函数通常用于需要快速定义简单函数的场景。
① lambda 函数的基本语法如下:
1 | lambda arguments: expression |
- arguments: 输入参数,可以是多个,用逗号分隔。
- expression: 一个表达式,返回值是这个表达式的计算结果。
② 示例
1 | # 创建一个简单的 lambda 函数 |
(2)应用(使用 lambda 函数作为参数)
lambda 函数常用于需要函数作为参数的场景,例如在 map(), filter(), 和 sorted() 函数中。
① map()
map()函数用于将指定函数应用于给定可迭代对象的每个元素,并返回一个迭代器map(function, iterable)- function: 要应用的函数(可以是
lambda函数) - iterable: 要处理的可迭代对象(如列表、元组等)
- 示例
1 | numbers = [1, 2, 3, 4, 5] |
② filter()
filter()函数用于过滤可迭代对象中的元素,返回满足条件的元素filter(function, iterable)- 遍历每个元素,如果满足 function 中的条件(返回 True),则保留该元素;否则,丢弃该元素
- 示例
1 | numbers = [1, 2, 3, 4, 5] |
③ sorted()
sorted()函数用于对可迭代对象进行排序,可以使用lambda函数自定义排序规则。sorted(iterable, key=None, reverse=False)- key 是一个函数,用于从每个元素中提取比较键
- 默认升序排列,reverse=True,则调整为降序
- 示例
1 | points = [(1, 2), (3, 1), (5, 0), (0, 3)] |
(3)注意
- 单行表达式:
lambda函数只能包含一个表达式,不能包含多个语句或复杂的逻辑。 - 可读性:虽然
lambda函数可以使代码更简洁,但在复杂的情况下,使用常规的def函数可能会提高代码的可读性。 - 命名:
lambda函数是匿名的,但可以赋值给变量以便后续使用。
9. 装饰器
9.1 概念
(1)定义
在 Python 中,装饰器(decorator)是一种用于修改或增强函数或方法行为的设计模式。装饰器本质上是一个函数,它接受另一个函数作为参数,并返回一个新的函数。通过使用装饰器,可以在不修改原始函数代码的情况下,添加额外的功能或行为。
(2)常见用途
- 日志记录:记录函数的调用信息。
- 权限检查:在执行函数之前检查用户权限。
- 缓存:缓存函数的返回值以提高性能。
- 输入验证:验证函数参数的有效性。
9.2 装饰器的基本语法
- 装饰器通常使用
@decorator_name语法来应用,放在被装饰函数的定义上方
1 | # 定义 装饰器 |
9.3 带参数的装饰器
- 装饰器也可以接受参数。为了实现这一点,通常需要在最外层再嵌套一层函数
1 | # 定义 含参数的装饰器 |
10. 数据结构
10.1 将列表当作栈使用
- 在 Python 中,可以使用列表(list)来实现栈的功能。栈是一种后进先出(LIFO, Last-In-First-Out)数据结构,意味着最后添加的元素最先被移除。
- 用 append() 方法可以把一个元素添加到栈顶,用不指定索引的 pop() 方法可以把一个元素从栈顶释放出来。
- 压入(Push): 将一个元素添加到栈的顶端。
- 弹出(Pop): 移除并返回栈顶元素。
- 查看栈顶元素(Peek/Top): 返回栈顶元素而不移除它。
- 检查是否为空(IsEmpty): 检查栈是否为空。
- 获取栈的大小(Size): 获取栈中元素的数量。
1、创建一个空栈
2、压入(Push)操作
- 使用 append() 方法将元素添加到栈的顶端
2
3
4
stack.append(2)
stack.append(3)
print(stack) # 输出: [1, 2, 3]3、弹出(Pop)操作
- 使用 pop() 方法移除并返回栈顶元素
2
3
print(top_element) # 输出: 3
print(stack) # 输出: [1, 2]4、查看栈顶元素(Peek/Top)
- 直接访问列表的最后一个元素(不移除)
2
print(top_element) # 输出: 25、检查是否为空(IsEmpty)
- 检查列表是否为空
2
print(is_empty) # 输出: False6、获取栈的大小(Size)
- 使用 len() 函数获取栈中元素的数量
2
print(size) # 输出: 2
10.2 将列表当作队列使用
- 在 Python 中,列表(list)可以用作队列(queue),但由于列表的特点,直接使用列表来实现队列并不是最优的选择。
- 队列是一种先进先出(FIFO, First-In-First-Out)的数据结构,意味着最早添加的元素最先被移除。
- 使用列表时,如果频繁地在列表的开头插入或删除元素,性能会受到影响,因为这些操作的时间复杂度是 O(n)。为了解决这个问题,Python 提供了 collections.deque,它是双端队列,可以在两端高效地添加和删除元素。
- collections.deque 是 Python 标准库的一部分,非常适合用于实现队列。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# 创建一个空队列
queue = deque()
# 向队尾添加元素
queue.append('a')
queue.append('b')
queue.append('c')
print("队列状态:", queue) # 输出: 队列状态: deque(['a', 'b', 'c'])
# 从队首移除元素
first_element = queue.popleft()
print("移除的元素:", first_element) # 输出: 移除的元素: a
print("队列状态:", queue) # 输出: 队列状态: deque(['b', 'c'])
# 查看队首元素(不移除)
front_element = queue[0]
print("队首元素:", front_element) # 输出: 队首元素: b
# 检查队列是否为空
is_empty = len(queue) == 0
print("队列是否为空:", is_empty) # 输出: 队列是否为空: False
# 获取队列大小
size = len(queue)
print("队列大小:", size) # 输出: 队列大小: 2
- 虽然 deque更高效,但如果坚持使用列表来实现队列,也可以这么做。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
queue = []
# 2. 向队尾添加元素,使用 append() 方法将元素添加到队尾
queue.append('a')
queue.append('b')
queue.append('c')
print("队列状态:", queue) # 输出: 队列状态: ['a', 'b', 'c']
# 3. 从队首移除元素,使用 pop(0) 方法从队首移除元素
first_element = queue.pop(0)
print("移除的元素:", first_element) # 输出: 移除的元素: a
print("队列状态:", queue) # 输出: 队列状态: ['b', 'c']
# 4. 查看队首元素,直接访问列表的第一个元素
front_element = queue[0]
print("队首元素:", front_element) # 输出: 队首元素: b
# 5. 检查队列是否为空
is_empty = len(queue) == 0
print("队列是否为空:", is_empty) # 输出: 队列是否为空: False
# 6. 获取队列大小,使用 len() 函数获取队列的大小
size = len(queue)
print("队列大小:", size) # 输出: 队列大小: 2
- 微信
- 支付宝






