CIFAR100 多模型训练结果及分析
一、自建网络
两层 CNN 网络
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: Adam
思路
CNN:Conv2d -> BatchNorm2d -> ReLu -> MaxPool2d
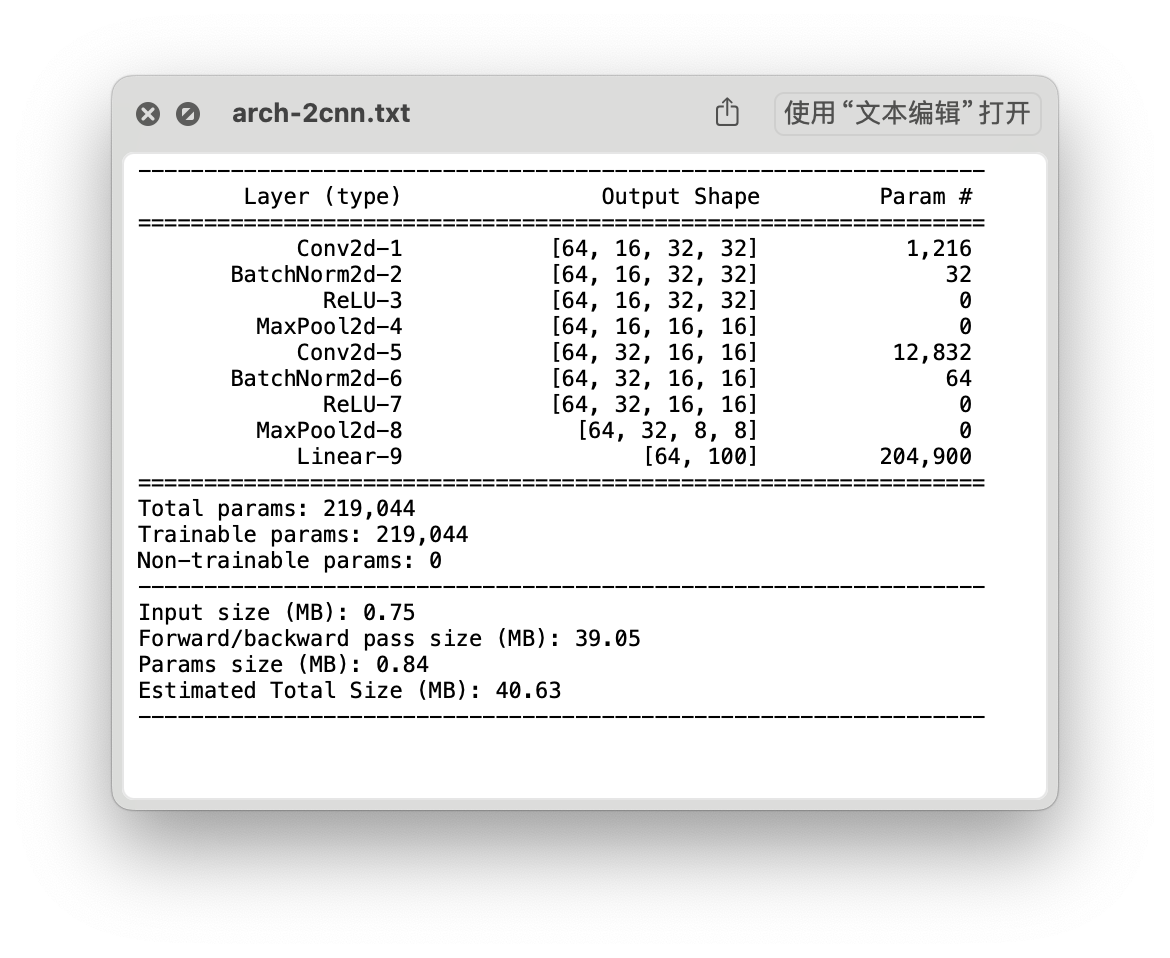
结构

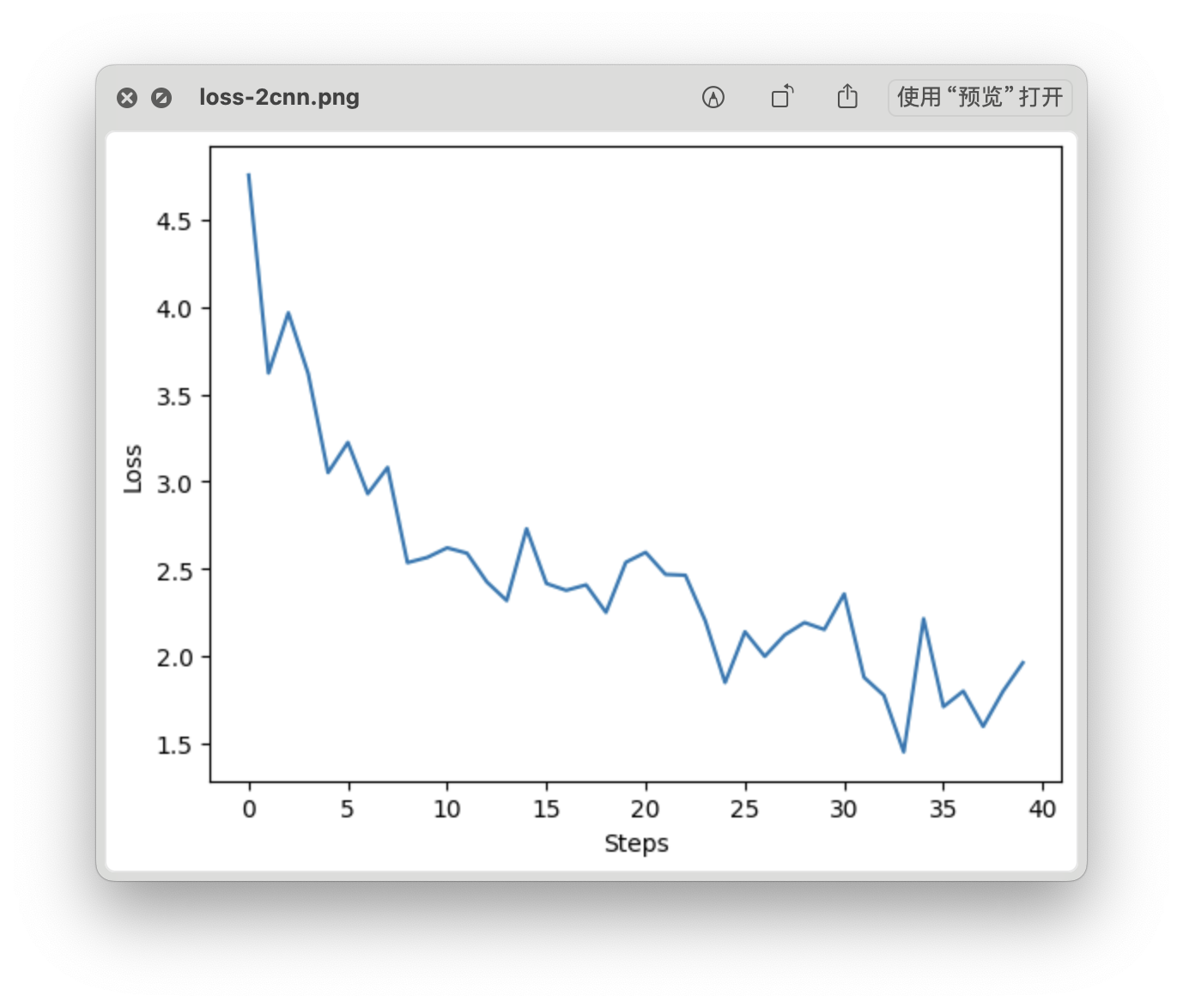
loss 曲线
- Time: 0:01:11.308311
- Min Loss: 1.4500
- Final Loss: 1.9618
测试集精准度
- 测试集精准度:39.75 %
三层 CNN 网络
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: Adam
思路
CNN:Conv2d -> BatchNorm2d -> ReLu -> MaxPool2d
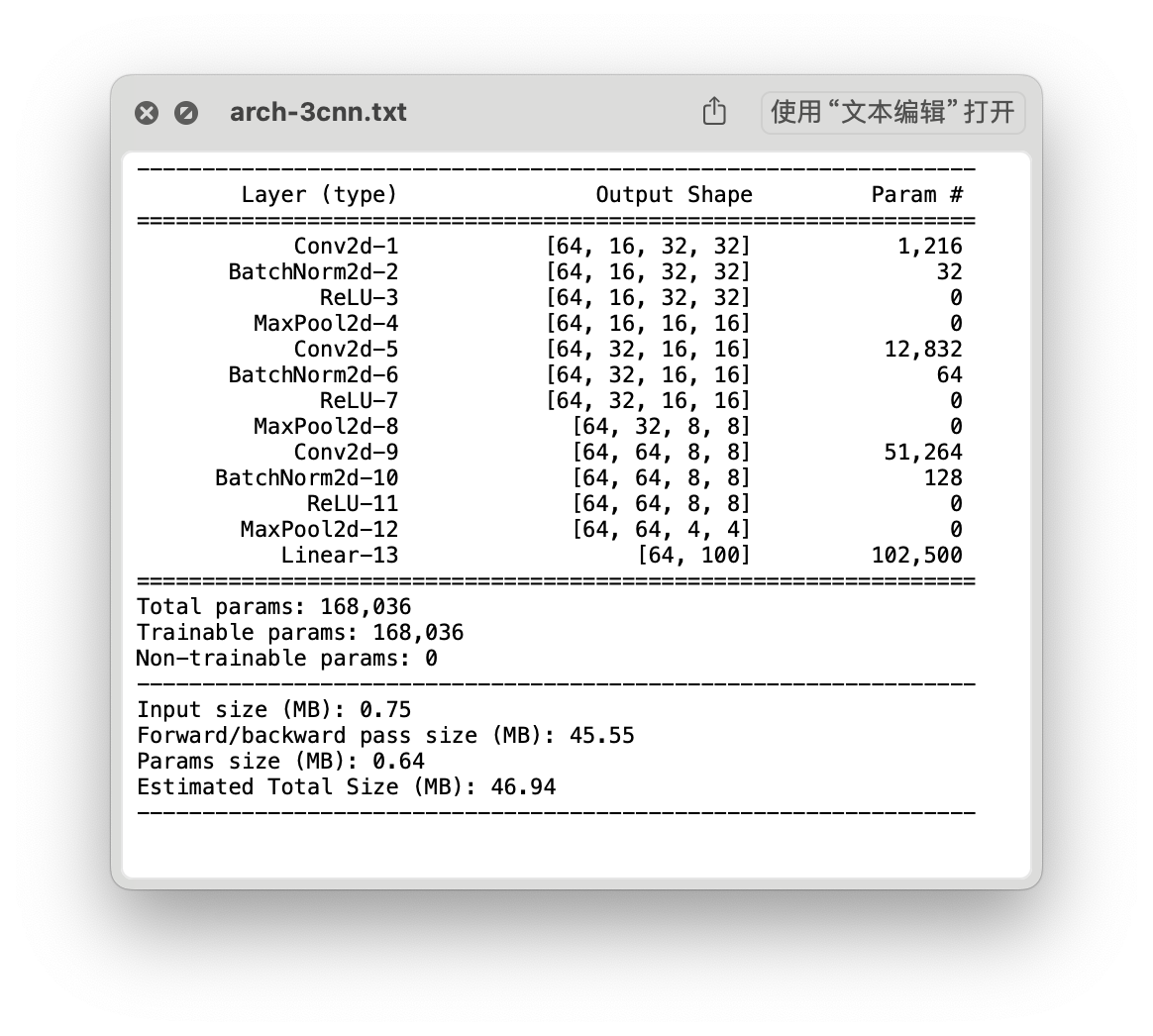
结构
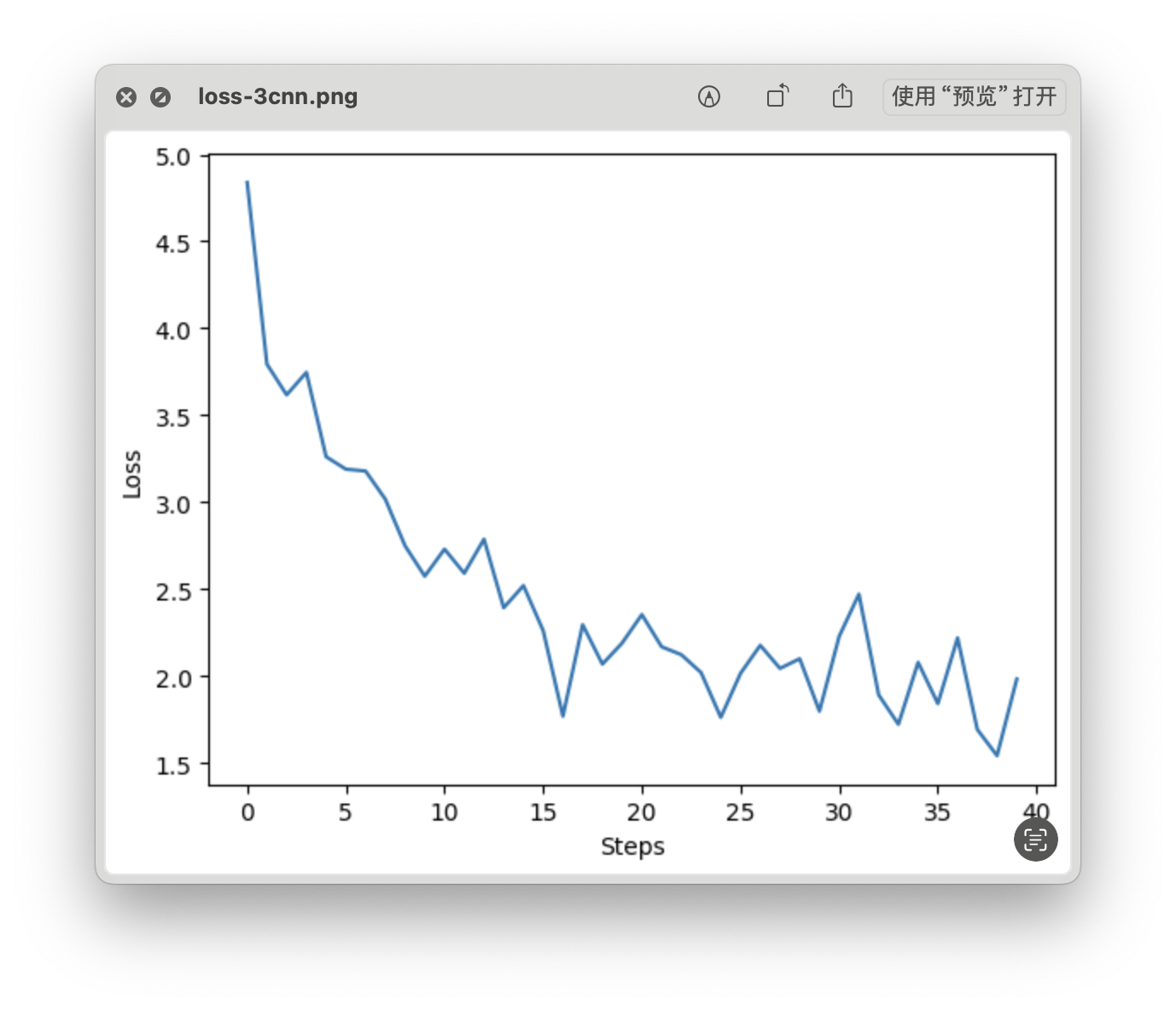
loss 曲线
- Time: 0:01:10.645922
- Min Loss: 1.5404
- Final Loss: 1.9817
测试集精准度
- 测试集精准度:44.14 %
五层 CNN 网络
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: Adam
思路
CNN:Conv2d -> BatchNorm2d -> ReLu -> MaxPool2d
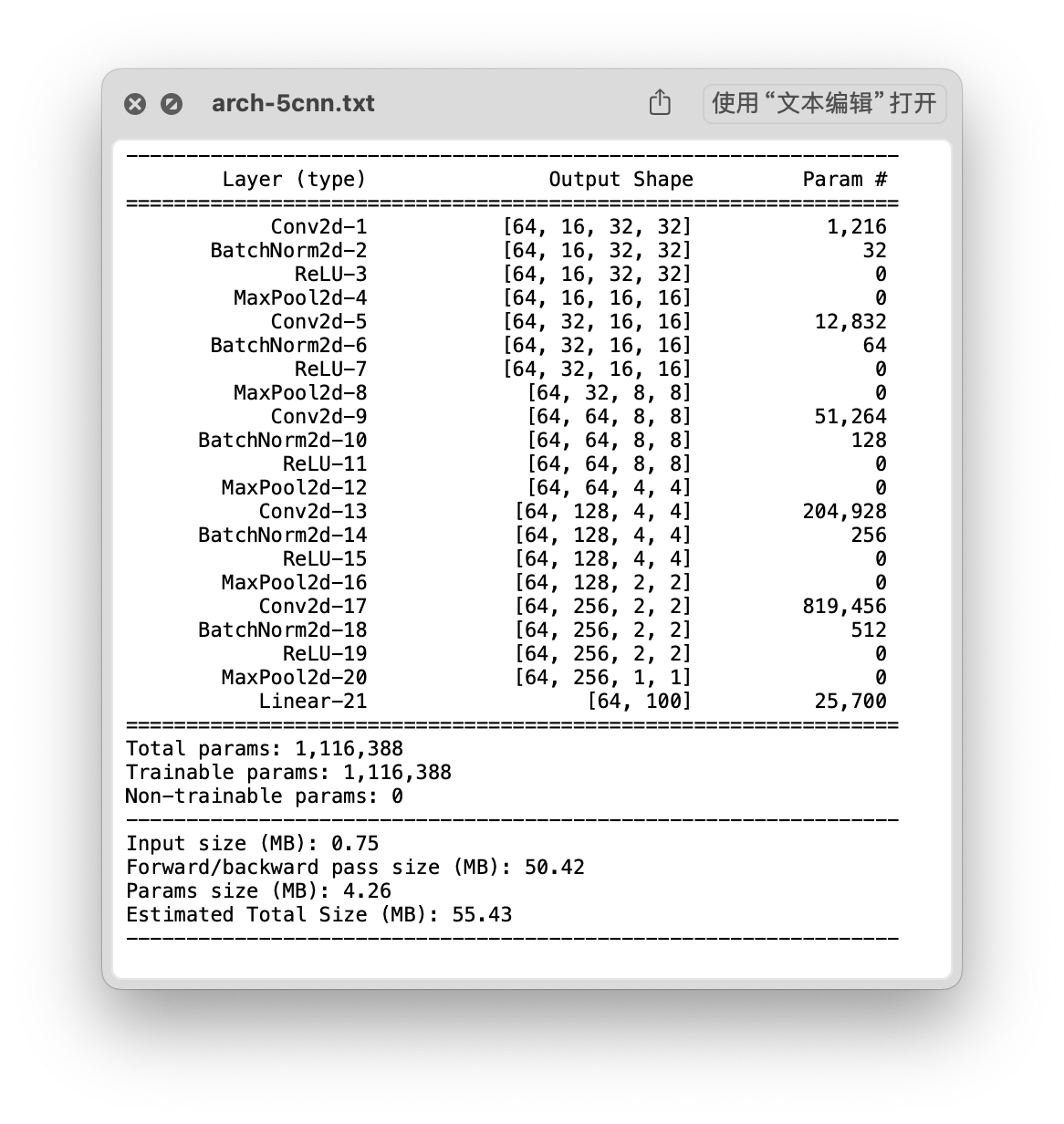
结构
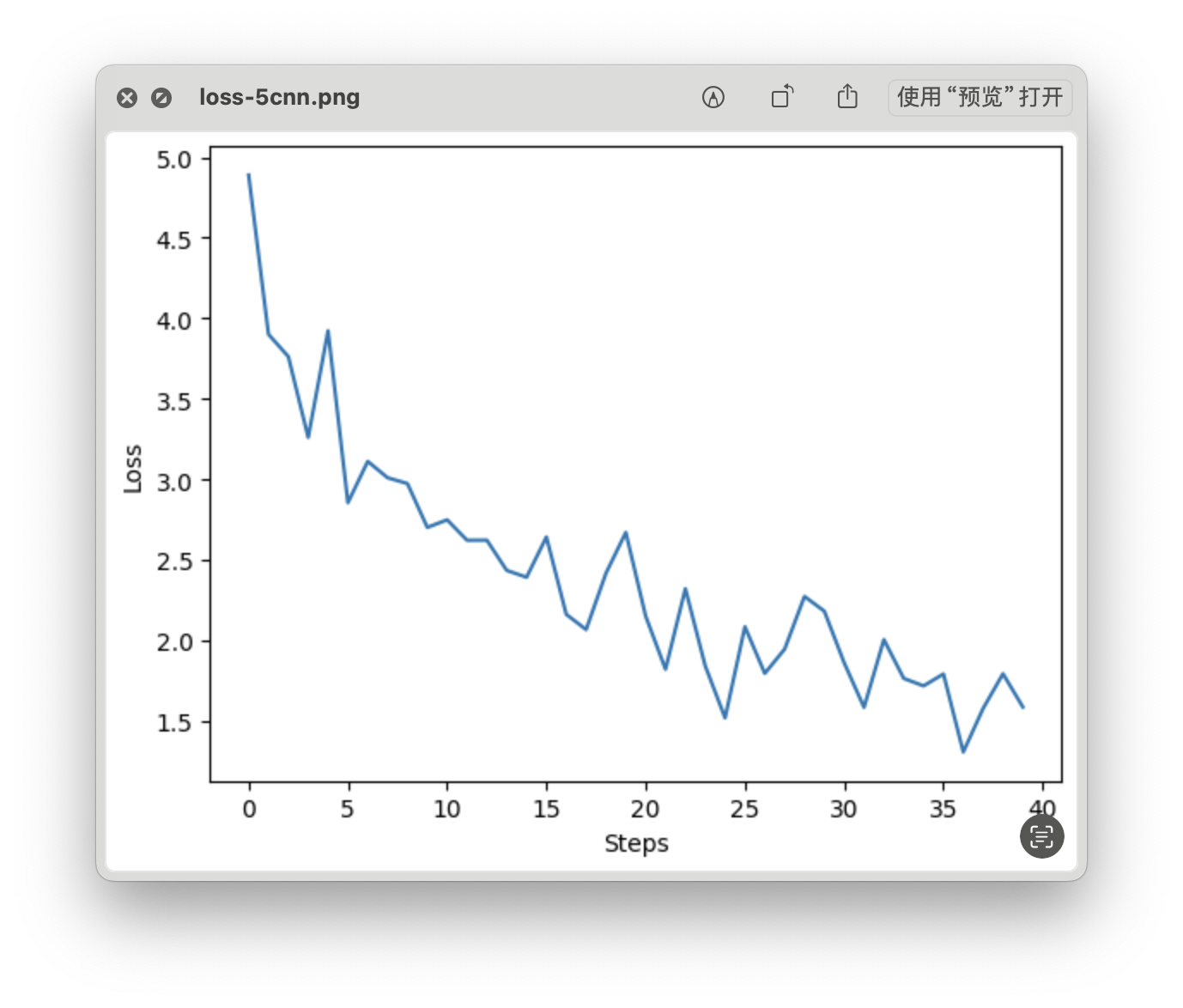
loss 曲线
- Time: 0:02:12.387121
- Min Loss: 1.3080
- Final Loss: 1.5872
测试集精准度
- 测试集精准度:44.20 %
二、经典 CNN 网络
VGG 19
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: SGD
思路
VGG 19 -> Transforms ( Resize + ToTensor + Normalize) -> Model Arch ( fc out 100 ) -> Fine Tune
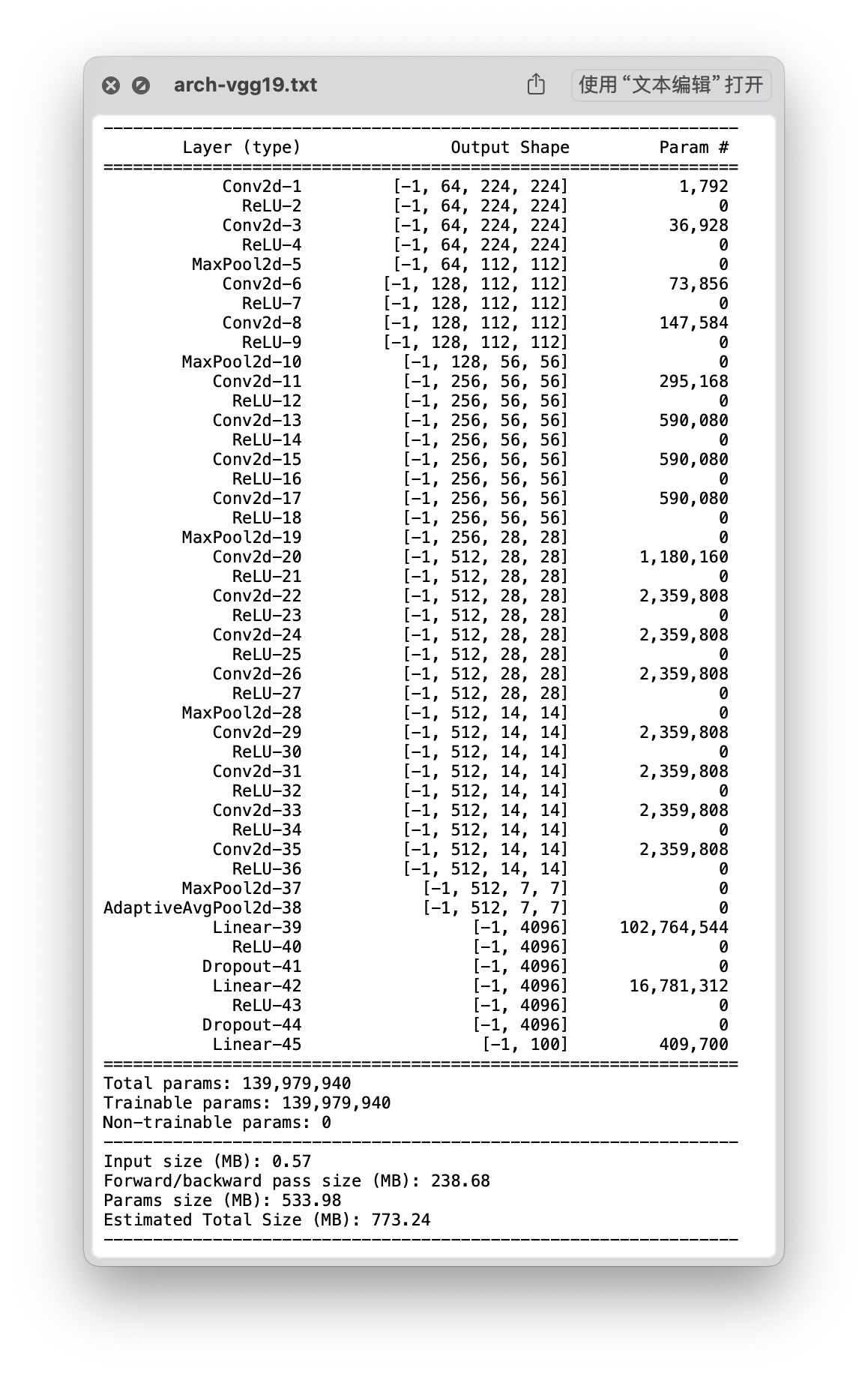
结构
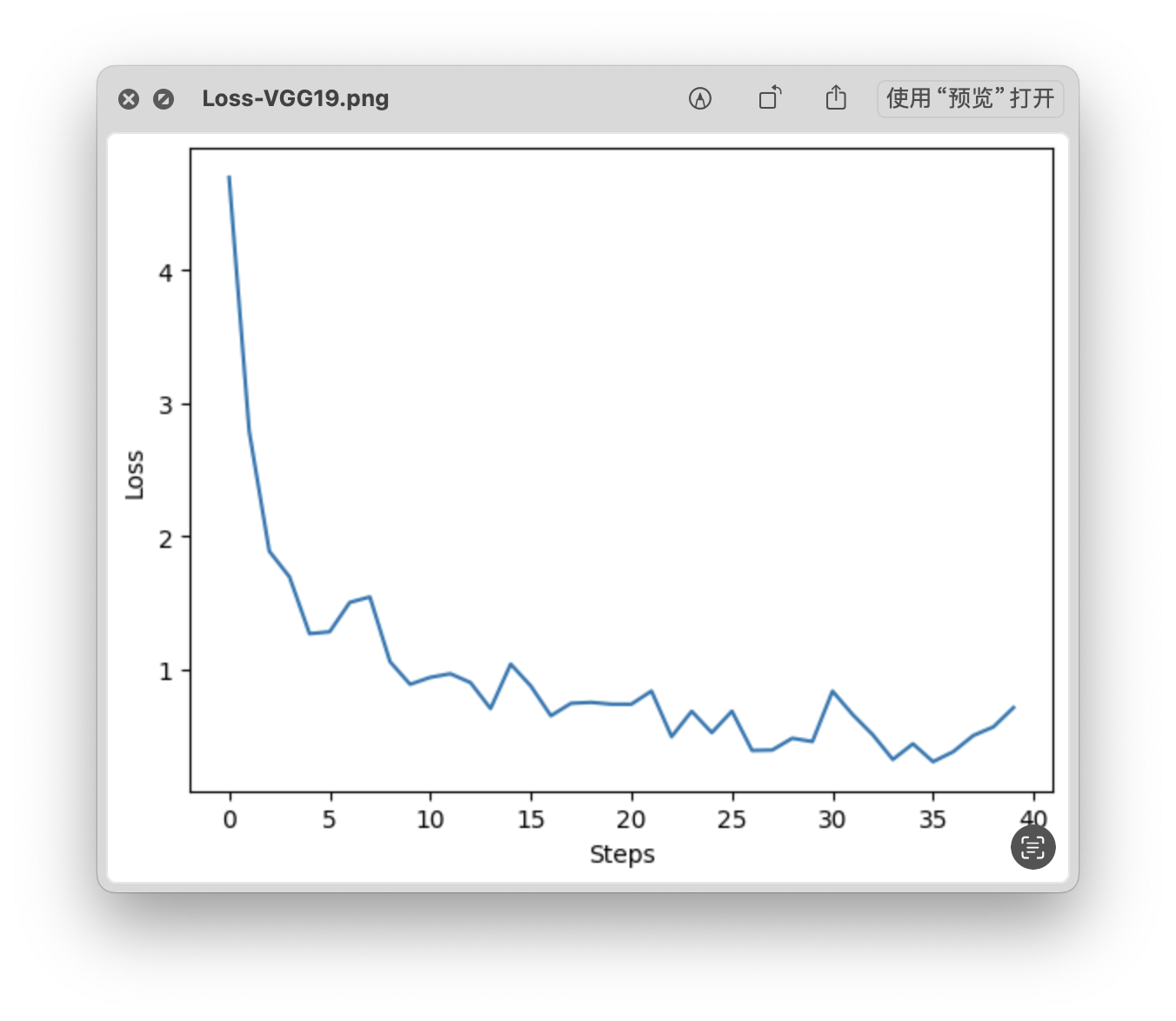
loss 曲线
- Time: 0:24:17.983430
- Min Loss: 0.3057
- Final Loss: 0.7126
测试集精准度
- 测试集精准度:71.61 %
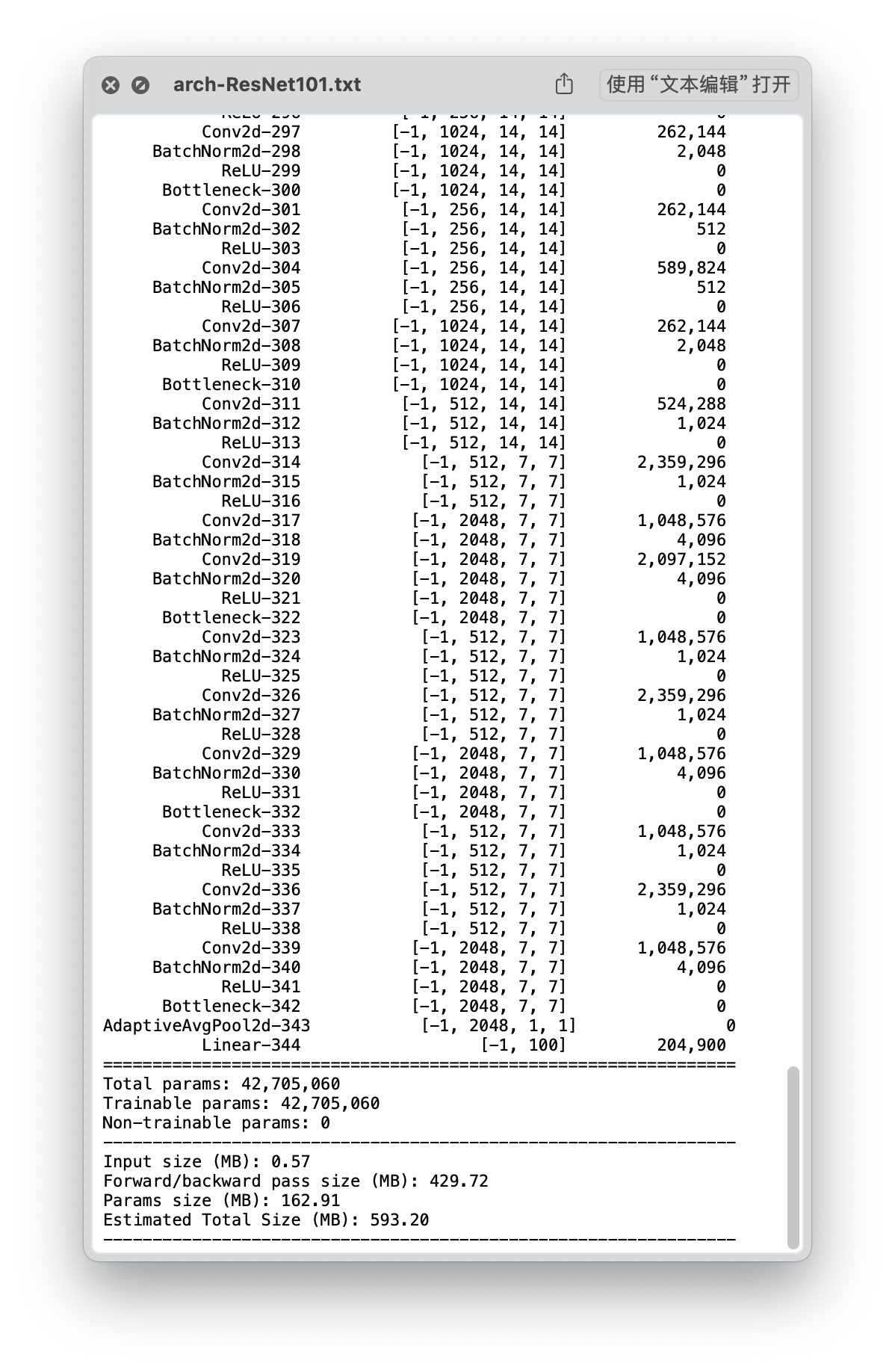
ResNet 101
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: SGD
思路
ResNet 101 -> Transforms ( Resize + ToTensor + Normalize) -> Model Arch ( fc out 100 ) -> Fine Tune
结构
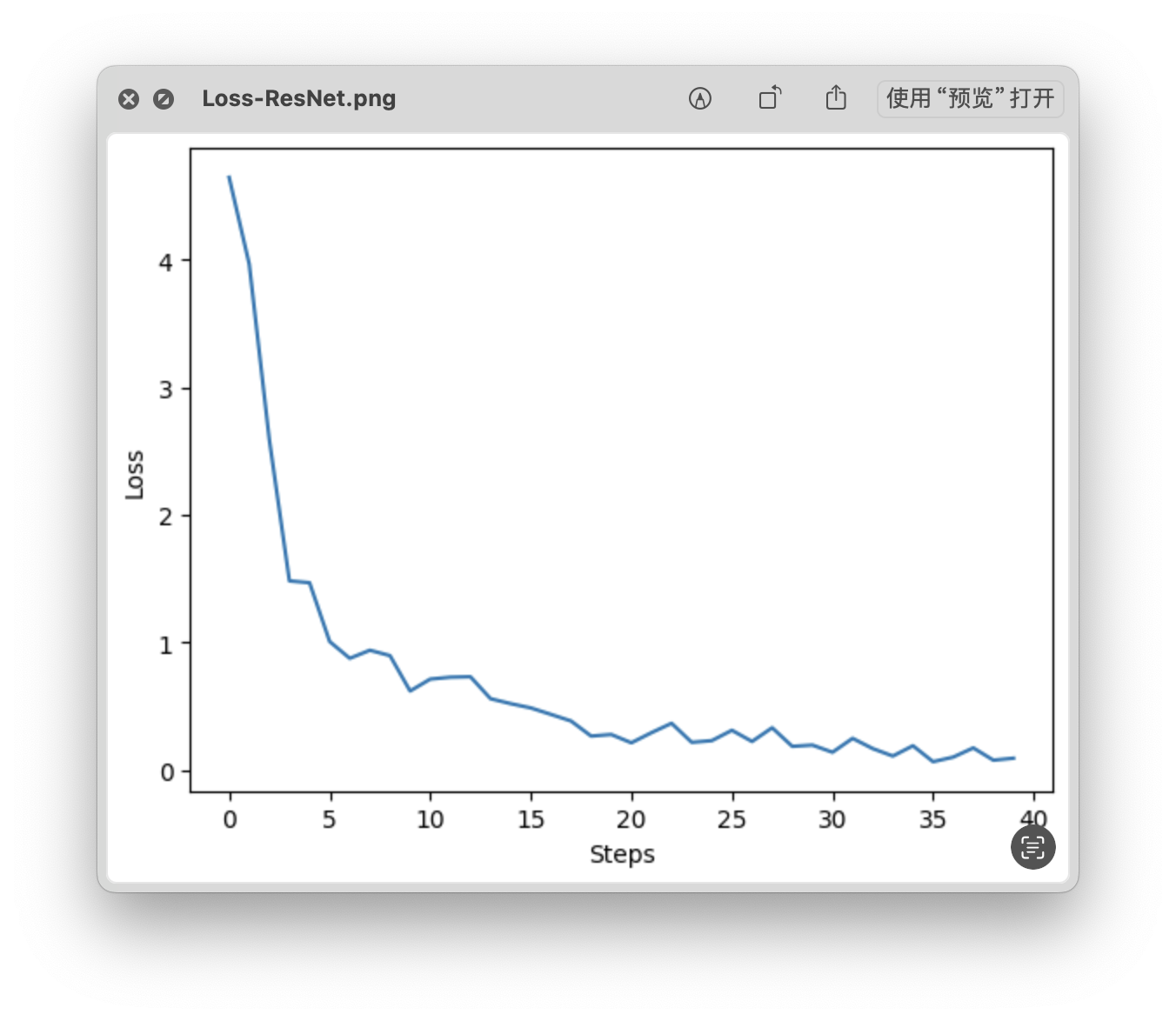
loss 曲线
- Time: 0:26:58.626524
- Min Loss: 0.0667
- Final Loss: 0.0942
测试集精准度
- 测试集精准度:83.92 %
三、 Vision Transformer 网络
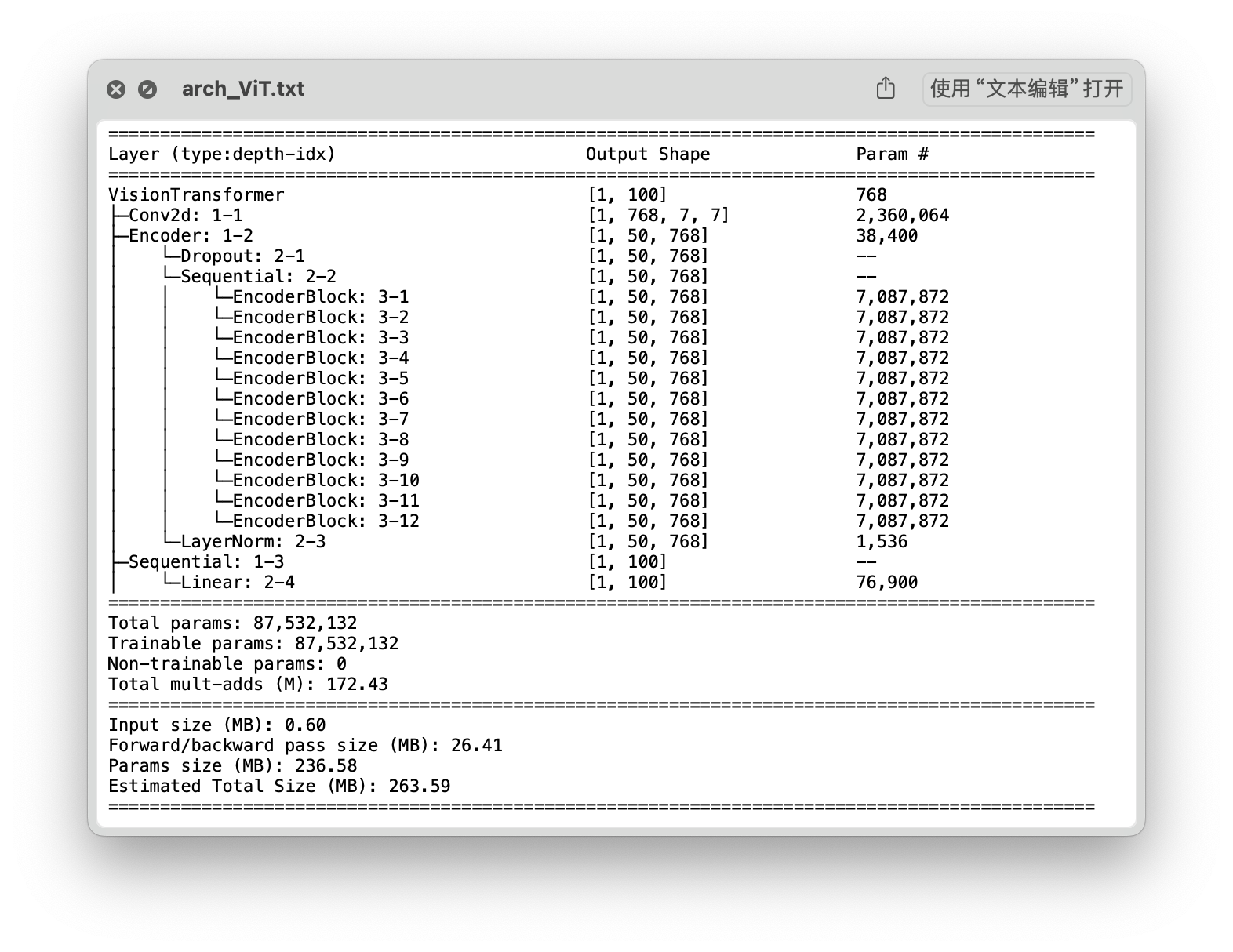
ViT_b_32
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: SGD
思路
ViT_b_32 -> Transforms ( Resize + ToTensor + Normalize) -> Model Arch ( fc out 100 ) -> Fine Tune
结构
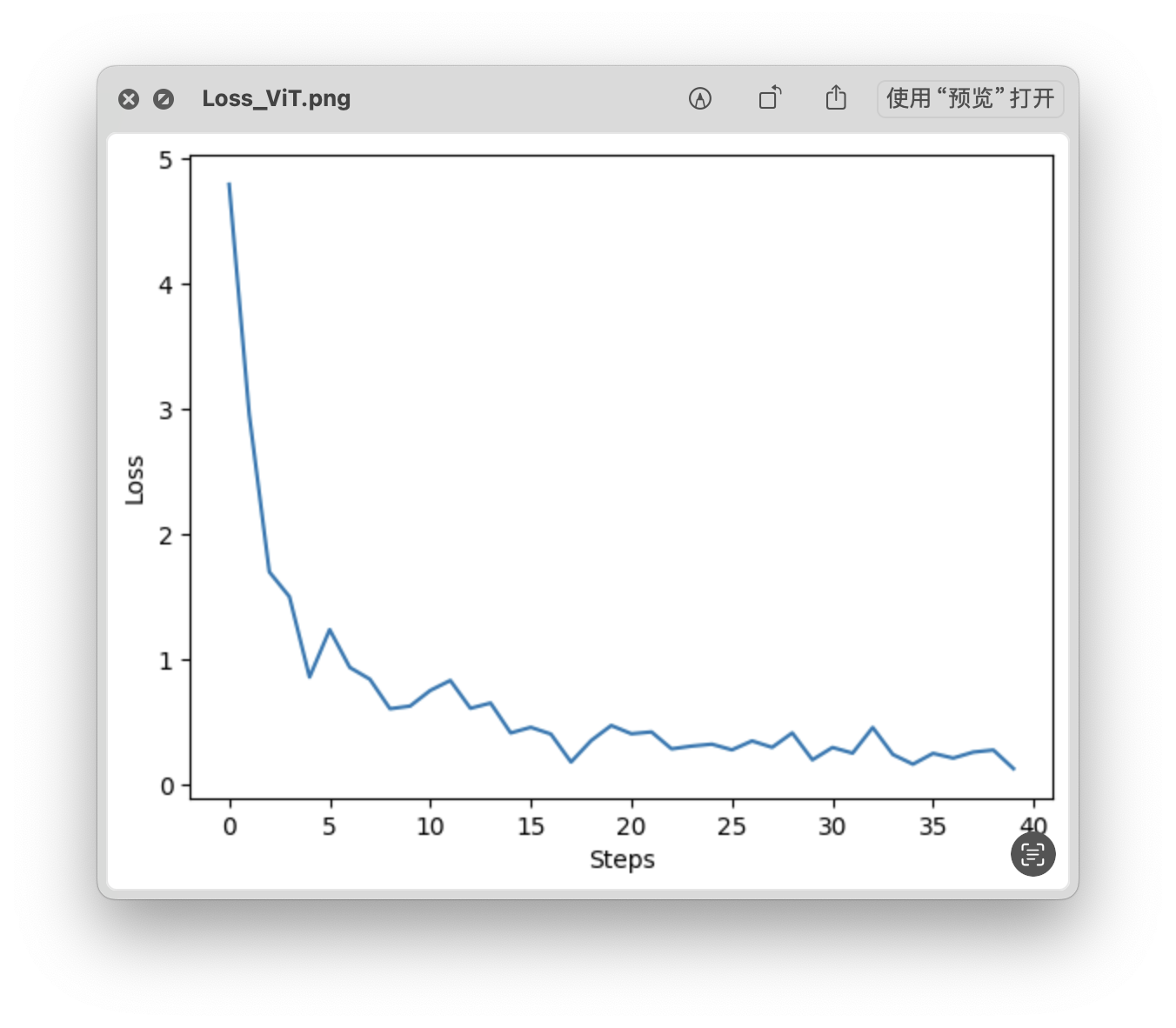
loss 曲线
- Time: 0:11:34.681656
- Min Loss: 0.1308
- Final Loss: 0.1308
测试集精准度
- 测试集精准度:84.34 %
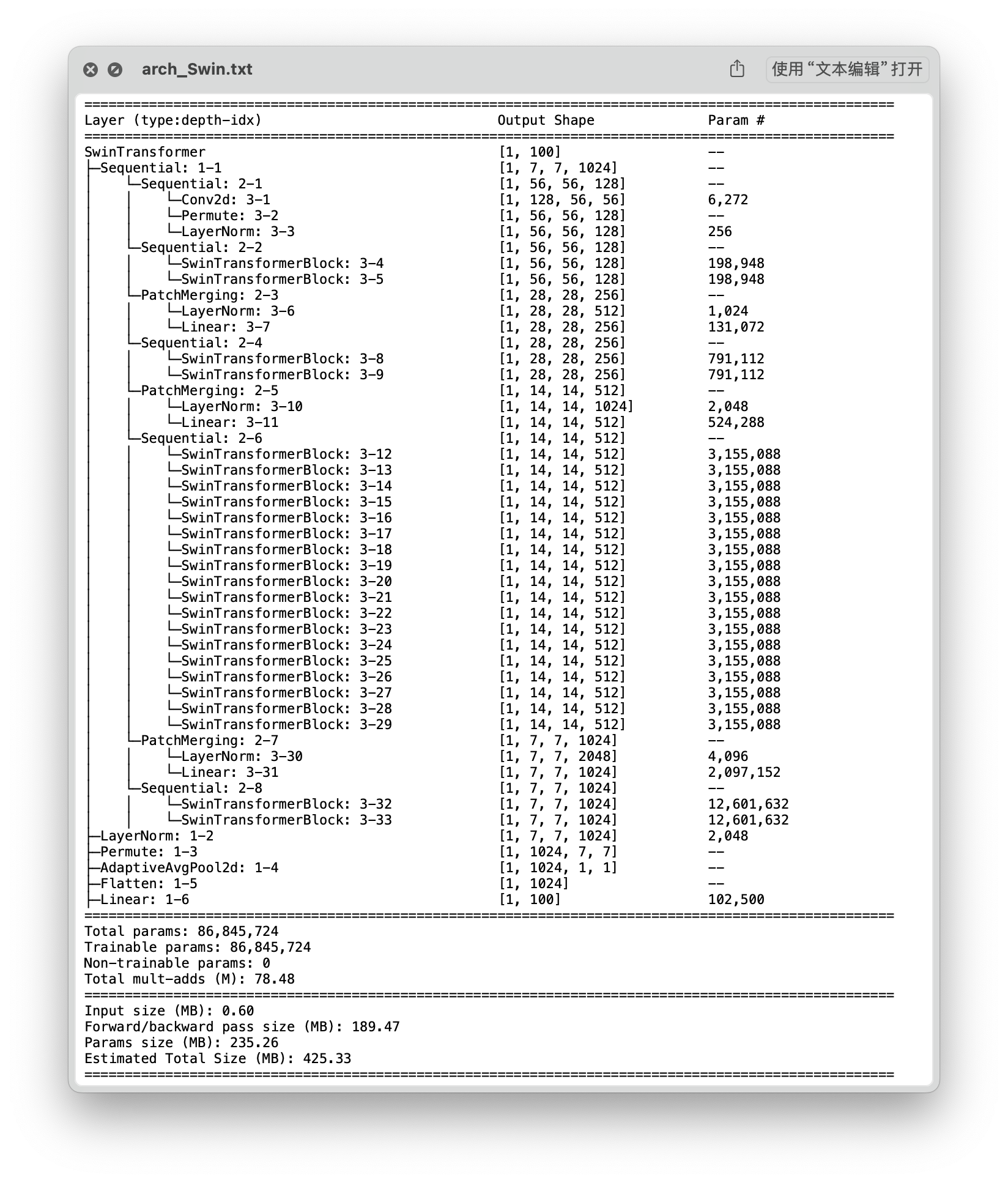
Swin_b
超参数
- batch_size = 64 (5000 / 64 = 782)
- epochs = 5
- learning_rate = 1e-3
- Loss: CrossEntropyLoss
- Optimizer: SGD
思路
Swim_b -> Transforms ( Resize + ToTensor + Normalize) -> Model Arch ( fc out 100 ) -> Fine Tune
结构
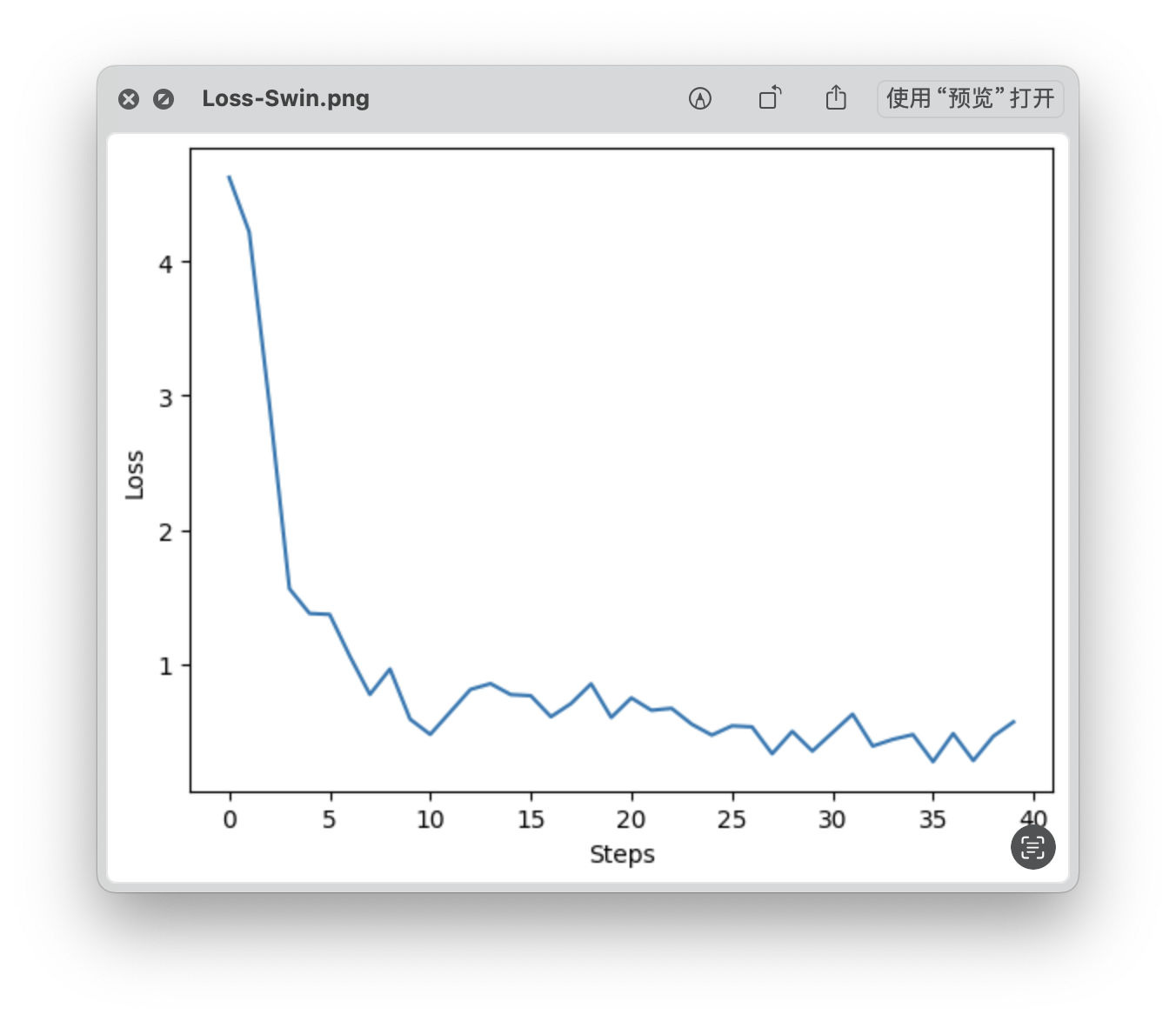
loss 曲线
- Time: 0:40:31.978593
- Min Loss: 0.2692
- Final Loss: 0.5661
测试集精准度
- 测试集精准度:83.53 %
四、对比分析
| Model | Total Params | Total Size | Min loss | Final Loss | Accuracy |
|---|---|---|---|---|---|
| CNN_2 | 219,044 | 40.63 | 1.4500 | 1.9618 | 39.75 % |
| CNN_3 | 168,036 | 46.94 | 1.5404 | 1.9817 | 44.14 % |
| CNN_5 | 1,116,388 | 55.43 | 1.3080 | 1.5872 | 44.20 % |
| VGG19 | 139,979,940 | 773.24 | 0.3057 | 0.7126 | 71.61 % |
| ResNet101 | 42,705,060 | 593.20 | 0.0667 | 0.0942 | 83.92 % |
| ViT_b_32 | 87,532,132 | 263.59 | 0.1308 | 0.1308 | 84.34 % |
| Swin_b | 86,845,724 | 425.33 | 0.2692 | 0.5661 | 83.53 % |
- 对比自建 CNN 网络
- 从 2 层 CNN 到 3 层 CNN 模型的总参数量有所下降,主要原因是 FC 层 Linear 函数的输入参数减少,导致了总参数量的下降。
- 从 2 层 CNN 到 3 层 CNN 模型准确率提升了约 4.39%;从 3 层 CNN 到 5 层 CNN 模型准确率几乎没有提升。虽然从 3 层到 5 层模型的总参数量扩大了约 6.64 倍,但是模型的性能没有显著提升,推测是因为此时模型深度的增加已经无法帮助模型学到更多有用的特征,且深度的增加也可能会导致模型出现过拟合现象,致使准确率无法得到进一步提升。
- 对比经典 CNN 网络
- VGG19 模型拥有近 1.4 亿的参数量,其规模也是本次测试中最大的模型。 VGG19 的测试结果(71.61%),也证明了使用更小的卷积核(3 * 3)并且增加卷积神经网络的深度,可以有效地提升模型的性能。
- ResNet101 通过引入残差块在网络内部跳跃连接,缓解了深度增加所导致的梯度消失的问题。从模型结果来看(83.92%),在增加模型深度,缓解梯度消失问题的同时也减少了参数量,相比于 VGG19 模型取得了更好的效果。
- 对比 Transformer 网络
- 本次所选用的 Transformer 网络都是该系列下的基础模型。ViT_b_32 模型 和 Swin_b 模型参数量相当,最后测试结果也较为接近,都具有较好的性能。
- 值得一提的是,在实际训练和测试时,Swin_b 模型对显存的占用非常高,训练时大约需要 15G 左右的显存空间,而测试时大概需要 30G 左右的显存空间,对硬件设备的要求很高。
五、总结与优化
总结
- 从自建 CNN 网络到 VGG 模型,可以看出增加网络的宽度和深度可以很好的提高模型的性能;但如果一直简单地增加深度,可能会遇到梯度爆炸或梯度消失的问题,对于前者可以尝试使用正则化的方式解决,但对于梯度消失的问题,就需要引入残差网络,在不增加额外参数的情况下,尽可能让深层次的模型得到充分训练,进而继续提升模型的性能,上述过程也在本次实验中得到了充分的验证。
- 转向 Transformer 架构,在 ViT 模型的思路下,用自注意力机制来捕捉全局图像信息,从而得到全连接的网络结构,能够很好的捕捉数据的特征;Swin 模型进一步采用分层的窗口化注意力机制和分层的网络结构,在降低计算复杂度的同时,也通过层级嵌套捕捉了多尺度的特征,使得模型在处理不同尺度的信息时更加灵活。
- 但是在本次实验中,ResNet 和 ViT 以及 Swin 的模型性能(测试集准确率)相近,没能很好的展现出 Transformer 架构在 CV 领域的巨大潜力。推测其中的原因,一是 ResNet 残差网络的性能确实很好,能够非常显著的降低梯度消失风险、提升 CNN 网络的性能;二是本次实验所选用的 CIFAR100 数据集相对原本的 ImageNet 而言更简单,用 ResNet 模型就足以捕捉其中的关键特征,能够较好的完成分类任务,ViT 和 Swin 的潜力没能得到充分发挥;三是模型的选用及训练策略的不足,本次实验选用的 ResNet 模型为 101 层,而 ViT 和 Swin 都只选用了 Base 模型,同时训练的 Epoch 较少,损失函数和优化器的选用没有做进一步的比对分析,学习率也没有做进一步的尝试。
优化
- 宏观层面,下一步将继续尝试不同的模型,结合模型结构和实验结果分析每种模型的特点、改进点。
- 微观层面,下一步将尝试调整训练策略,增加 Epoch 的同时引入验证集,根据验证集准确率等指标提前停止训练防止模型过拟合现象的产生,同时将尝试不同的损失函数和优化器,以及综合使用 Warm up、余弦退火等技巧逐步改善学习率,进一步提升模型的性能。
此文章版权归 AngFff 所有,如有转载,请注明来自原作者
- 微信
- 支付宝

